I know from my experience working for and with enterprise companies that keeping dozens or hundreds (or thousands!) of apps up to date is complicated. Much of my career in tech has been spent in and around the cloud-based platform and modern application development spaces in an attempt to help solve this problem for customers. But I also spent time as a product manager working directly with developers, so I’ve seen how even with automated CI/CD pipelines, modern app architectures, and robust app platforms, it ultimately comes down to effectively managing a code base and often tackling mountains of tech debt along the way. I remember having to spend precious sprint cycles on cleaning up and refactoring whole swaths of code instead of focusing on delivering features for end users.
I’ve also seen over the past many years how even the most successful moves to cloud can still lead to a lot of challenges when it comes to data migration. Plus, with the explosion of Internet-of-Things (IoT) devices, it’s getting more and more difficult to ship data off to the cloud for processing. It’s been fun to watch the trend towards edge computing to combat these obstacles, but of course, that brings its own set of challenges from a scaled management perspective. I remember working on this almost ten years ago with automated bare metal hardware deployments, but now there is even more to consider!
These are hardly solved problems, but thankfully, a few of my former colleagues have ended up at companies where they are addressing them with some very innovative solutions. In my career, I’ve been extremely lucky to meet and work with some truly smart people, and one of the perks of knowing so many sharp folks in tech is that just by following their career paths, I can keep up to date with a lot of industry trends and get exposed to technologies that are new to me. This is how I became aware of two open-source projects that I’ve recently been exploring...
OpenRewrite
OpenRewrite is an open-source tool and framework for automated code refactoring that’s designed to help developers modernize, standardize, and secure their codebases. With all the tech debt out there among enterprise teams managing large Java projects in particular, OpenRewrite was born to work with Java, with seamless integration into build tools like Gradle and Maven. But it’s now being expanded to support other languages as well.
Using built-in, community, or custom recipes, OpenRewrite makes it easy to apply any changes across an entire codebase. This includes migrating or upgrading frameworks, applying security fixes, and imposing standards of style and consistency. The OpenRewrite project is maintained by Moderne, who also offers a commercial platform version that enables automated refactoring more efficiently and at scale.
EVE (Edge Virtualization Engine)
EVE is a secure, open-source, immutable, lightweight, Linux-based operating system designed for edge deployments. It’s purpose-built to run on distributed edge compute and to provide a consistent system that works with a centralized controller to provide orchestration services and a standard API to help manage a fleet of nodes. Think about having to manage hundreds (or more!) of small-form-factor devices like Raspberry Pis, or NUCs that are running in all sorts of places across different sites.
With EVE-OS, devices can be pre-configured and shipped to remote locations to limit the need for on-site IT support. And with its Zero Trust security model, it protects against any bad actors who may easily gain access to these edge nodes that often live outside of the protection of a formal data center. Because it is hardware agnostic and supports VMs, containers, Kubernetes clusters, and virtual network functions, it also has the ability to run applications in a variety of formats. EVE-OS is developed by ZEDEDA specifically for edge computing environments and aims to solve some of these unique challenges around running services and applications on the edge. They also offer a commercial solution for more scalable orchestration, monitoring, and security.
Let’s Build Something!
There isn’t exactly an obvious intersection of interest here, but bumping into these projects independently, right around the same time, got me thinking about how I could experiment with both of them and build something that balances practical OpenRewrite usage with something deployable via EVE-OS. This is what I came up with:
Write a very simple but somehow outdated Spring Boot REST app
Use OpenRewrite to refactor and “modernize” it
Containerize the resulting modern app
Deploy it to an EVE-OS “edge node” [locally]
Of course, this only scratches the surface of the potential that these technologies have, but it turned out to be a pretty fun exercise for getting started by just dipping my toe a bit into each of these areas. In case you’re interested in getting your feet wet too, I’ve summarized the steps I took below, including a link to the code I used.
Refactoring a Simple Legacy Spring Application
As a developer, my Java knowledge is admittedly relatively surface level, but I do know enough to write a working REST controller. Here’s my simple class that just calls a basic endpoint and spits back out its JSON result:
My Spring skills are pretty outdated, so I would say a refactor is most certainly in order. Accordingly, I figured I’d use OpenRewrite to accomplish three primary things when updating this code:
Use the newer dedicated @GetMapping as an alternative for @RequestMapping
Use the SLF4J Logger instead of the elementary System.out.println
Upgrade from Spring Boot 2.x to 3.x
I didn’t show my pom.xml file here, but I used version 2.3 and will upgrade to 3.2
There are definitely other things I could choose to update. For example, I didn’t opt to write test cases in a test class, but if I had I could also have migrated from JUnit 4 to 5. I also saw some articles that suggested updating RestTemplate to RestClient or even the asynchronous WebClient. I didn’t find any recipes for this, though I could maybe tackle writing a custom one, but I left that out of scope for now. I’m satisfied with this limited example.
Since I first learned to build Spring apps with Maven, that’s what I opted to use here (but there is support for Gradle as well). The basic Maven plugin command to run for OpenRewrite is mvn rewrite:run, but that requires defining configuration and parameters in pom.xml. I wanted to keep everything dynamic and on the command line, so I passed everything in using the -D flag to define the properties:
You can see the three active recipes that I passed in to perform the tasks I outlined above. The first two are recipes straight from the OpenRewrite catalog. The last one is too, sort of, but in order to pass it the necessary configuration options, I created a rewrite.yml file in the root of the project:
type: specs.openrewrite.org/v1beta/recipe
name: com.example.ReplaceSystemOutWithLogger
recipeList:-org.openrewrite.java.logging.SystemOutToLogging:addLogger:"True"loggingFramework: SLF4J
level: info
This specifies what logging framework and log level to use. The active recipe references whatever name is used here, hence com.example.ReplaceSystemOutWithLogger.
And that’s it. Running the mvn command above does the magic, fixing the pom.xml file to reference Spring Boot 3.2 and updating the controller code as follows:
Notice @GetMapping has replaced @RequestMapping and the System.out.println has been moved to use a logger instead. The code still builds and runs fine, but now it’s up-to-date!
Here’s the repository with the full set of code: https://github.com/bryanfriedman/legacy-spring-app. It has the original code in main and the updated code on the refactor branch so you can use git diff main..refactor or your favorite diff tool to compare.
Deploying the Refactored App to an EVE “Edge Node”
Now that we have a running, refactored app, let’s deploy it to “the edge.” But first, we need an EVE node. The easiest way to setup a virtual EVE node locally, it turns out, is to use a tool called Eden (clever) as a management harness for setting up and testing EVE. Eden will also help us create an open-source reference implementation of an LF-Edge API-compliant controller called Adam (also clever) which we will need to control the EVE node via its API. Eden is neat because it lets you deploy/delete/manage nodes running EVE, the Adam controller, and all the required virtual network orchestration between nodes. It also lets you execute tasks on the nodes via the controller.
To accomplish this setup, I mostly followed an EVE Tutorial that I found which was extremely helpful. It outlines the process of building and running Eden and establishing the EVE node and Adam controller. However, this tutorial was written for Linux, so I ran into a few snags that didn't work in my MacOS environment. As such, I ended up forking eden and tweaking a few minor things just to get it to work on my machine. This mostly involved getting the right qemu commands to make the environment run. You can see the specifics here in the forked repo. And of course, while the tutorial describes how to run a default nginx deployment to test things out, I obviously deployed this Spring app instead. I also discovered that I needed to specifically configure the port forwarding for the deployed pod in question in order to reach the app for testing.
Here are the slightly modified steps that I took:
Prerequisites
I installed all the following prerequisites if they weren't already installed, using brew where possible, or otherwise downloading and installing: make, qemu, go, docker, jq, git.
Prepare and Onboard EVE
Start required qemu containers:
$ docker run --rm--privileged multiarch/qemu-user-static --reset-pyes
Build Eden ( used my fork as indicated above):
$ git clone https://github.com/bryanfriedman/eden.git &&cd eden/
$ make clean
$ make build-tests
Setup Eden configuration and prepare port 8080 for our app:
$ ./eden status
$ ./eden eve onboard
$ ./eden status
Deploy the app to EVE
Deploy the Spring app from Docker Hub:
$ ./eden pod deploy --name=eve_spring docker://bryanfriedman/legacy-spring-app -p8080:80
Wait for the pod to come up:
$ watch ./eden pod ps
Make sure it works:
$ curl http://localhost:8080
Conclusion
After all this work, I’m not exactly an expert in automated refactoring or edge computing all of the sudden, but I do have a much better understanding of the technologies behind these concepts. While they might not seem particularly related, I can definitely see how a company might be interested in both of these paradigms as they look to modernize their apps at scale and potentially look at migrating them to run at the edge. With just these rudimentary examples, you can start to see the potential of the power they can provide at scale.
SpringOne Platform is known for showcasing some of the most compelling customer stories you’ll find at any tech conference. Last year, we heard from many leading companies about how they are getting better at software. This year, there were moreamazingtales of transformation from enterprise leaders. It’s safe to say that “it’s still about outcomes.”
But behind all these great outcomes is a lot of cool tech! I attended quite a few technology-focused sessions this year. They got me excited about the various announcements throughout the week. There was all the stuff you’d expect at a conference called “SpringOne Platform” — new versions of Spring components, Java 11 talk, and platform releases for PCF and PKS. Then there were so many other tech topics that showed up too. I found these five to be the most intriguing:
Pivotal announced that it “has a team working on contributing Cloud Foundry support to open source Spinnaker.” Spinnaker already supported AWS, Azure, GCP, Google App Engine, Kubernetes, and other platforms. Now, Pivotal is ensuring that Cloud Foundry is a first-class citizen of Spinnaker. Jon Schneider covered this on the main stage and in detail in a breakout session.
Why Is It Cool?
Spinnaker is one of the few true multi-cloud delivery platforms. Started by Netflix, it has contributions from Google, Amazon, Microsoft, and now Pivotal. There are two essential components: a multi-cloud application inventory and pipelines.
The inventory piece is critical, since applications rarely live on a single platform. Spinnaker presents an aggregate view of all your applications, clusters, and instances. (It can do this without even having deployed them.) This allows users to determine their application health and state across platforms. It also means Spinnaker is distinctly able to run out-of-band processes. As a result, it supports running things like vulnerability scanning or chaos engineering tooling at build time.
Along with the inventory, as you’d expect from a CD solution, Spinnaker offers pipelines. Even if you are a user of Concourse, Jenkins, or other CI tools, Spinnaker is best suited to help with these delivery aspects of your pipeline.
Presentations about security topics don’t always offer the most gripping demos. Still, I was very interested in a few of the breakout sessions on CredHub, the credential manager that’s baked right in to Cloud Foundry. It turns out, security can be seductive.
In his example, a webhook object in Kubernetes injects CredHub into pods on the cluster. Then application code in the pods may access secrets from the credential store. It was a slick demo and an incredible way to show off CredHub’s simplicity and strong capabilities. Peter’s CredHub with Kubernetes code is on GitHub!
Peter is amazing. Much respect to what he is doing wirh credhub. Three talks at @s1p !! https://t.co/YNgMQtMZL2
CredHub offers a secure way for humans and applications to interact with secrets. With Pivotal Application Service and the CredHub Service Broker, developers never have to know or see any passwords. Passwords are only available to application containers with authorized access. Each application container includes a signed certificate and key. This key provides identity when communicating with CredHub.
How Can I Get Started?
There are tons of amazing CredHub resources out there. Check out some of the recent blog posts from my colleagues:
What’s a tech conference today without the mention of serverless? SpringOne definitely had its share of serverless moments. Of course, Pivotal Function Service (coming soon) got a shout-out from Onsi Fakhouri. Plus, there were plenty of other details covered about Knative and riff at the conference.
At SpringOne Platform last year, Pivotal announced riff, an open source serverless framework. Earlier this year, Pivotal revealed that riff was replatformed on top of Knative. This is the technology that is driving Pivotal's serverless future. Knative and riff will power the yet-to-be-released Pivotal Function Service.
Containers and Kubernetes are hot topics at conferences. What's even hotter? Taking control of the application lifecycle in a container-centric world. Developers want a fast and secure way to get from source to container. It’s something the Cloud Foundry community has had solved for a while with buildpacks. Now this solution is expanding.
What Happened?
Day 1 main stage had a surprise ending from Stephen Levine from Pivotal and Terence Lee from Heroku. They introduced an effort to bring buildpacks to the broader cloud-native community. It's called Cloud Native Buildpacks, and it joins the CNCF as a sandbox project today.
Introducing Cloud Native Buildpacks. At #SpringOne, Pivotal and Heroku gave you a sneak peek at this platform-agnostic tool that's now part of the CNCF. pic.twitter.com/oAn5qjBsNE
Buildpacks are an “opinionated, source-centric way to build applications.” They are a big part of the magic behind Cloud Foundry’s `cf push` experience. Buildpacks detect the kind of app then fetch and install the tools needed to run it. For operators, the ability to manage a curated set of buildpacks is attractive. It also allows for rapid, secure patching en-mass using remote image layer rebasing. All the while, developers simply focus on delivering value for their own customers. The new specification and set of tools enable buildpacks to be used on any platform.
Reactive programming is not a new concept for SpringOne Platform attendees. I vividly remember Phil Webb’s awesome keynote from last year comparing blocking with non-blocking. (Who can forget the swimming ducks and cats?) This year there was more Reactive-related fun.
What Happened?
There were two impressive keynotes relevant in the Reactive programming space. First, there was the introduction of the non-blocking relational database connectivity driver, R2DBC. We also learned about RSocket, a new message-based application network protocol.
Why Is It Cool?
In two articles on InfoQ, Charles Humble examines both R2DBC and RSocket. He does an amazing job explaining the advantages of Reactive programming. As Pivotal's Ben Hale explains in one article, "Reactive programming is the next frontier in Java for high efficiency applications." He points out two major roadblocks to Reactive programing: data access, and networking. R2DBC and RSocket aim to address these problems.
I found RSocket to be particularly fascinating. In the main stage presentation, Stephane Maldini gave a brief but helpful history of TCP and HTTP. He framed RSocket as an alternative to these protocols while sort of bringing the best of each to bear. Rather than simply request/response, RSocket offers four different interaction models. (They are Request/Void, Request/Response, Request/Stream, and Stream/Stream.) What's more, it's language-agnostic, bi-directional, multiplexed, message-based, and supports connection resumption. It kind of blew my mind.
Last week I visited Boston for the first time and attended my very first Cloud Foundry Summit. I also took the opportunity while I was there to make my first visit to Fenway Park. It was a fabulous week of firsts for me.
As with any conference, one measure of excellence is the amount of quality examples of customer success stories. It's also nice to see compelling demos of new and interesting technology. CF Summit 2018 did not disappoint in either of these departments. In fact, my colleagues have already written quite eloquently on thesetopics. So I'll spend some time on something else that was a key theme of the conference.
To be sure, Cloud Foundry tech has always championed interoperability. It's multi-cloud. It's polyglot. It's OCI-compliant. The Open Service Broker API was even born of Cloud Foundry. (It's now been adopted by the Kubernetes community.) It was fantastic to see these concepts expand even more this year.
Indeed, it's nice to see this interoperability movement flourish. Still, I couldn't help but think of how it relates to another critical part of Cloud Foundry's success.
Opinions Are Like... Everybody's Got One
Yes, it embraces interoperability. Yet Cloud Foundry has always been billed as an opinionated platform. So it's important to point out that "interoperable" and "opinionated" are not mutually exclusive. But they are equally important characteristics for an effective platform. Interoperability without opinions runs the risk of becoming complicated or difficult to use. But of course, opinions without interoperability may prove irrelevant. After all, a good platform has to be able to handle many types of workloads. It should integrate with the services and technologies that you need to use.
So both are important. But in my previous life working in IT, I'll admit I wasn't in the opinionated camp. I didn't even understand it as a concept. I generally went for selecting software with the ultimate flexibility. What I didn't realize was how often this led to analysis paralysis and decreased productivity.
I remember one of the last projects I worked on. We were selecting a software product for financial planning and reporting. Ideally, we'd have found a solution that did 80% of what was required. We should have reevaluated the actual importance of the other 20% we thought we needed. Instead, we focused on that 20% until we settled on something that could handle it. Then implementation details, changing requirements, and complex technology got in the way anyway. As I recently heard one industry analyst say, "Choice is not a differentiator."
Unfortunately, I had not yet learned about the value that opinionated software can bring. It's about a simplified user experience and increased productivity. I like how Duncan Winn describes it in his book, Cloud Foundry: The Definitive Guide:"
When you look at successful software, the greatest and most widely adopted technologies are incredibly opinionated. What this means is that they are built on, and adhere to, a set of well-defined principles employing best practices. They are proven to work in a practical way and reflect how things can and should be done when not constrained by the baggage of technical debt. Opinions produce contracts to ensure applications are constrained to do the right thing.
Platforms are opinionated because they make specific assumptions and optimizations to remove complexity and pain from the user. Opinionated platforms are designed to be consistent across environments, with every feature working as designed out of the box. For example, the Cloud Foundry platform provides the same user experience when deployed over different IaaS layers and the same developer experience regardless of the application language. Opinionated platforms such as Cloud Foundry can still be configurable and extended, but not to the extent that the nature of the platform changes...
That last part is key: "...can still be configurable and extended..." Remember, interoperability still matters. It just can't happen at the expense of complexity. That's why something like the Open Service Broker API is so elegant and powerful.
There's an interesting nugget there at the beginning of Duncan's description too: "...they are built on...well-defined principles..." It's not only how the software works but also what it's built on. The architecture is opinionated as well. A lot of times that means selecting a particular set of technologies or patterns and incorporating them together in a specific way. Basically: curation.
An Ounce of Productivity is Worth a Pound of Curation
Okay, so this play on a Benjamin Franklin quote isn't exactly a perfect analogy. But the point is, as I've recently heard a customer quoted: "Curation is how we get stuff done!"
In the consumer world, we enjoy the benefits of curation daily. We trust companies like Netflix to suggest movies and television we will like. We look to Amazon to tell us what we like to buy. Our Facebook and Twitter feeds are filtered for us. These are the modern giants of content curation. They use algorithms and AI to keep things relevant, but people still drive the behavior. Plus, think about traditional television or radio news, or even used bookstore or boutique owners. We embrace curation in our daily lives.
In the business and IT world, however, it seems like curation is often avoided. Remember the 20%? Sometimes the customer knows better and doesn't buy into an opinionated architecture. They insist on defining it themselves. It's true that curation may not be for everyone. Under the right circumstances, though, it can help save a lot of time and headaches. Determine where you are on the curation scale and pick the right solution. If you trust the curator, they can help.
At CF Summit, I attended many talks about Kubernetes and its role within the Cloud Foundry ecosystem. As Onsi Fakhouri spoke about at SpringOne Platform late last year, it's an and conversation, not or. It's not about Kubernetes vs. Cloud Foundry, but rather how can they interoperate? Or, more specifically (and more opinionated), how should they interoperate?
This was a popular topic at CF Summit this year. Right now, Cloud Foundry has a few ways it interoperates with Kubernetes. Most prominently it's a separate container runtime (as opposed to the application runtime). Some things fit better on the container runtime (like stateful workloads, ISV container images). Some are made for the application runtime (12-factor apps, microservices, etc.). The opinion right now is that it all depends on the use case.
Other examples and conversations about Kubernetes interoperability showed up at the conference too. There were products that include CF running on top of K8s and demos showing K8s running within CF. As a first-time attendee, it was amazing to see the open discussion and sharing of ideas. That's the beauty of open source software and its community. It can evolve to incorporate (read: "curate") other growing technologies and find the right (read: "opinionated") way to put it all together. (For Cloud Foundry, it doesn't just mean Kubernetes either. Look at how the code base has begun incorporating Envoy for another example.) It will all come together in the way that makes the most sense for the user experience. In the end, that's all that should matter.
It's All About the Outcomes
Technology is a great enabler. We can't do technology for technology's sake. Containers are cool. Machine Learning is fun. Yes, there are some amazing pieces of tech out there. Except it's not about the tech itself, but rather what it enables for its users. It's the user experience, the productivity gains, the value, that matters.
Ultimately, technology should be about doing things better, faster, more reliably. That's the level that all software curation conversations should arrive at: customer outcomes. Whatever the future of Cloud Foundry and Kubernetes brings, we can't forget the fundamental goal: build software better.
Richard Watson from Gartner led a customer panel in the final round of keynotes at SpringOne. In it, he asked the company leaders what blew their minds during the conference. Of course, it got me thinking about what blew my mind at SpringOne Platform this year. Here's what I came up with, in no particular order.
I've been to a fair amount of conferences in my career, and this one was truly top notch. Conferences are often draining and it can be hard to keep up the excitement throughout the week. This event felt elevated from the moment I checked in at Moscone Center. You had to be there to feel it I guess, but all these things contributed to the greatness:
Signage and graphics looked amazing and were well themed. Complete with ASCII art and 8-bit renditions of the keynote speakers.
The main stage room was incredible, and the keynote speaker lineup was tremendous. It was a nice mix of tech talks, customer stories, and philosophy. Everyone seemed to engage for the full two hours. That's quite a feat.
The breakout sessions were right-sized, on point, and on schedule. And they were well attended! During sessions, the hallways were empty, with only a few stragglers at some booths or on laptops.
It had a fun vibe! Lots of discussion and socializing. Plenty of power strips everywhere. Coffee, drinks and food available at regular intervals. There were even old school arcade games!
When I saw links to GitHub repos in the Comcast and Intuit sessions, it was another mind blowing moment. It's been a long road, but we're finally there. Open source is in the enterprise for real. And I'm not talking about using open source software, though that's impressive too. I mean that enterprises are contributing code back to the open source community.
The announcement of PCF 2.0 highlighted some key Windows-related features. First, native Windows Server 2016 containers for .NET workloads. In one demo, Richard Seroter showed off ssh-ing directly into a Windows container. Typing dir into an ssh window may feel weird, but what a relief for .NET developers.
Speaking of feeling weird, how about displaying hardware at a software conference? That's right, PCF 2.0 will have beta support for Azure Stack. The Microsoft booth had a working Dell EMC server cabinet to showcase it. Mind blown.
BTW, during my #springone demo today, I showed off native Windows Server Containers in @pivotalcf. That's a working "cf ssh" command against a Windows app. Now. Not months from now! pic.twitter.com/VaAwFLqS4k
There were plenty of cloudfamous folks to be found in both the keynotes and breakout sessions. I'm not ashamed to admit I had my fair share of geek out moments during the week. I've followed a lot of these tech personalities on Twitter for a long time, even before I joined Pivotal. So getting to see or meet a lot of them in person for the first time was super cool. It's like bringing my Twitter feed to life.
I know that's a lot of name dropping. But it really was an incredible showing of very smart and talented professionals. The best part about all of this is how lucky I feel to be able to call so many of these people colleagues now. That realization is what blew my mind the most.
Starting off with the incomparable @cote talking #DevOps (sort of): Why organizations try it and what they struggle with when trying to improve how they build software. #springonepic.twitter.com/Uocwn8pAG5
Finally, I have to drop a few more names so I can share the amazing interactions I had with the analyst community. RedMonk's James Governor gave a thought-provoking keynote. Richard Watson of Gartner led the aforementioned customer panel. And Dave Bartoletti from Forrester gave a great session on cloud native ops superpowers.
But it was the personal interactions I had with these analysts this week that had the most impact for me. It's one of the great privileges I have in my role at Pivotal now. I get to have insightful, relevant conversations with these folks. Doing it in person is always an even more superior experience. The questions they had about platforms and the product landscape alone blew my mind. I appreciated their thoughts and observations this week. I look forward to more mind-blowing 😲 action next year in Washington, D.C.
Last session of the day for me. Ending it right - with @DaveBartoletti sharing some cloud native ops superpowers. Good slide on abstractions spawning new abstractions and driving the demand for automation. #springonepic.twitter.com/Fh8GWne8Hq
After two full days at my very first SpringOne Platform, my head is spinning. At times I've felt excited, lucky, proud, impressed, and overwhelmed -- sometimes all at the same time. So what's the best thing to do when I'm feeling all the feelings? Write about it!
I've been having lots of thoughts that I can't shake in two key areas so I want to share about them.
PCF 2.0: It's a Cloud!
During the keynote on Tuesday, among a slew of announcements, Onsi Fakhouri unveiled PCF 2.0. I'm not going to get into the details here, but you can (and should!) read all about it and watch Onsi's incredible presentation if you haven't already.
A few months ago, I caught a glimpse of what was coming with PCF 2.0. When I saw a rough sketch of the "four pillars" on a whiteboard, I thought "Hey! That's a cloud!" It sounds silly to me now. Of course it's a cloud! It's right there in the name. Pivotal Cloud Foundry. And PCF 2.0 is its natural evolution.
To be clear, I'm not interested in having a "what is the cloud?" discussion. (I already get that with my family when they ask me what it is that I do.) Still, it's fair to say that the cloud encompasses many things these days. Public clouds now offer such a breadth of products and services that it's hard for some customers to keep up. At the same time, customers have more and more types of workloads and want more and more choices.
All the public clouds have an app service, a container service, and a functions (serverless) service. Some have more than one of each! They all also offer many data persistence and messaging services. So the concept of Pivotal Cloud Foundry offering these same products makes total sense. PCF is staying just opinionated enough. Like Richard Seroter commented in his summary of Day 1, customers will have choices, but not too many. The reality is that customers are running in on-premise data centers. They need workloads to run in hybrid or multi-cloud environments. IaaS isn't enough to constitute a "private cloud" anymore. But PCF 2.0 sure is. (And it's not even limited to that. It runs on public clouds too, remember!)
Everyone at SpringOne Platform seems pretty pumped about the announcements. But I've heard of other folks wondering why Pivotal introduced PKS when they already have PAS. Some may wonder why anyone would still use PAS once they have PKS. And of course, there are many who don't yet understand what role serverless has to play and why PFS is even a thing. It's simple. They are all choices. Did anyone ask Amazon why they didn't kill their app service once they launched a container service? As Onsi said in his talk, the conversation is not an "OR" conversation. It's an "AND" conversation. PCF will be able to handle all customer workloads.
During Wednesday morning's keynote, I felt a little like a kid eating ice cream for the first time. It was riveting watching Kim Bannerman and Meaghan Kjelland do a PKS demo and seeing Mark Fisher show off riff. There is such an exciting future for PCF and I'm stoked I get to go along for the ride.
SpringOne Platform is full of developers and technology enthusiasts. There are plenty of tech talks and deep dives into code and platform architecture. I love that stuff and I attended a few sessions like that. Mostly though, I opted to attend the more customer-driven sessions. I haven't yet gotten to talk to enough customers in my time here, so I wanted to see the success stories up close.
See, I worked in IT at a large enterprise for 11 years. I saw how things run in an organization like that. I've been gone for more than 3 years, but I still know people there. Not very much has changed. They can get VMs provisioned a little faster now, but that's about it. So while I work for a company whose mission is to "transform how the world builds software," my experience in enterprise IT is so tainted, it has still been hard to fathom that it's actually possible.
But believe me, it is. Digital transformation is real, and it's spectacular. It's true that "digital transformation" as a term may be over used. It's probably the phrase I heard the most during all the sessions (aside from maybe "we're hiring"). The thing is though, buzzword or not, companies are actually doing it. And Pivotal is making it possible.
I listened to industry giants from many sectors — telco, banking, insurance, government, automotive — all tell amazing stories. It was inspiring. Refreshing even. It was beautiful. I found myself feeling sorry for my younger self, stuck in the past and trapped in a cloud-foreign world. It may sound hyperbolic, but I'm not kidding when I say there were moments of shock and awe. It's like meeting Big Foot. You've heard the rumors, you know the legend, but it's not real until you see it.
Of course, these companies' journeys aren't over. Far from it. They know that. They all said it. But they know the path now. They have the confidence they need to move forward. Or at least to move. Pivotal showed them the way and continues to partner with them on their journey. Like Onsi said, it's all about learning.
Scotiabank built banking-as-a-service on @pivotalcf and turned a 185 year-old bank into an “API-driven bank of the future” with more than 3000 deploys a month. #springonepic.twitter.com/OK9GvPwOuD
Hearing from @miralebl about how her team worked to “bring value to customers” at @LibertyMutual by letting developers focus on the business value apps can provide, not the infrastructure or network. #springonepic.twitter.com/yOnf745JuX
— DormAIn 🧟♀️ (aka "part of the problem") (@DormainDrewitz) December 6, 2017
“We changed the world, but the world also changed us... We weren’t born digital.” Niki Allen shares the 3 E’s she used to transform @Boeing. Very impressive. #springonepic.twitter.com/CG3UPHROeR
Fascinating talk from Lt. Col. Enrique Oti about how @DIU_x is helping the US Air Force use software to solve real problems, like tanker planning. “Saving 100s of 1000s of gallons of fuel.” #springonepic.twitter.com/Q3MPRZqLCv
Todd Hall from @Ford sharing their cloud native journey. Adopted @springboot + @pivotalcf and formed an “enablement” team. “We don’t want governance, we want to offer compelling solutions and suggestions to solve specific business problems.” #springonepic.twitter.com/N1w6Tzl1RP
Once again I'll look at three major public cloud players (AWS Elastic Beanstalk, Microsoft Azure App Service, and Google App Engine), as well as a third-party option that can run on a public or private cloud (Pivotal Cloud Foundry).
FULL DISCLOSURE: I work for Pivotal. I’ve also worked in the IaaS product space for 3 years. I have more than 10 years of experience working in enterprise IT. I’d like to believe I can remain pragmatic and present a fair view of related technologies.
I'm still not going to pick a winner at the end or make any claims about price or performance along the way. I'm focusing on the ongoing maintenance and management of the app once it's deployed. As before, I'm only interested in exploring the experience that each service provides.
By no means will I (or could I) cover everything required to keep an app up and running. I'll examine three key areas of Day 2 operations — observability, resilience, and patching.
Observability
The term "observability" comes from control theory and linear dynamic systems. It's "a measure of how well internal states of a system can be inferred by knowledge of its external outputs." In the software world, there are probably some differing opinions about its meaning. It sometimes gets used synonymously with "monitoring" and "logging."
In her post "Monitoring and Observability", Cindy Sridharan does a nice job of breaking it down. She borrows from Twitter's Observability Engineering Team's charter, and I like the definition. Observability is a superset of things. It has monitoring, but it also includes log aggregation, alerting, tracing, and visualization.
For each PaaS, I'll review some of the features offered that relate to any of these areas.
Note: The public clouds do tend to have a standalone service that covers lots of these features. Amazon has CloudWatch, Azure has Azure Monitor, and Google has Stackdriver. I'll try not to stray too far from the PaaS itself, and won't go into a ton of detail on these offerings. I'll just highlight where it's relevant and integrates with the PaaS product.1
Spring Boot Actuator
Since I'm running a Spring Boot app, I would be remiss not to first mention its Actuator. The Spring Boot Actuator exposes handy built-in HTTP endpoints for monitoring an application. (It supports adding custom endpoints as well.) For example, a /health endpoint shows application health information. This can be useful when setting up alerts to notify operators if a status changes from UP to DOWN for instance.
(By default, most of the endpoints are not routable without authentication. This is easy to enable with Spring Security, but I disabled it for the purposes of this exercise.)
I'll take advantage of the /health endpoint when using various platform monitoring features.
AWS Elastic Beanstalk
From a UI perspective, AWS does a nice job of making the observability features easy to find. There are menu items on the left navigation for Logs, Health, Monitoring, and Alarms. The Health section shows an overview of the application status. It includes other metrics like response codes, latency, and CPU utilization. (A similar view is also available from the CLI by using eb health.)
By default, it uses a TCP connection on port 80 to determine application health. We can set it to use a specific HTTP request instead from the Health section of the Configuration area. We'll start by setting the "Application health check URL" to the /health endpoint.
This sets the health check URL for the load balancer that sits in front of the application. We could also modify the Elastic Load Balancer (ELB) health check settings directly if we chose to. It supports different timeout and interval durations as well as customizable thresholds. This is set through the Load Balancer area of the EC2 service.
Back in the EB console, the Monitoring dashboard offers some nice visualizations on metrics like requests, health, and latency. It's also customizable, depending on what CloudWatch metrics are available.
This is the place where Alarms can be set up as well to send notifications based on certain thresholds. Here, I've set up an Alarm to notify me when CPU usage goes above 90% for 5 minutes.
And finally, Logs. You can easily download the last 100 lines or the full set of logs through the UI. As I mentioned last time, there is no simple interface for streaming or viewing them. Not a big deal, but you're stuck downloading and viewing in your browser or favorite text editor.
The last 100 lines option concatenates the most common logs together, but only the last 100 lines of each. The full log download isn't aggregated at all. Web server, application server, errors, platform operations— they each have their own output.
Downloading logs as above (or using eb logs) is what I used to do basic troubleshooting to get the app up and running. These logs only stick around for 15 minutes, so there are some options for log persistence. For one, they can be rotated and published to Amazon S3. AWS also offers integration with their CloudWatch monitoring service. This is the way to get streaming logs if you want them.
After enabling log streaming in the Software Configuration section, logs appear in CloudWatch. From there, they can be viewed in real time or sent off to Elasticsearch or S3 as needed.
Azure App Service
As with everything in Azure, the user interface can feel overwhelming at times. To discover what monitoring options Azure offers, I found this overview document helpful. It's more about monitoring Azure services holistically, but can be applied here too. It describes three tools and gives examples of when to use which one, which is useful. The tools are Azure Monitor, Application Insights, and Log Analytics.
The Azure Monitor interface is the consolidated UI view for all these services. From there you can create and configure metrics and alerts. Remember, this is a global view across all Azure resources, so you always have to target the specific App Service. Alternatively, you could access these settings on the App Service blade. Metrics are available on the "Overview" dashboard linked to from the top of the App Service left menu.
By default, visualizations appear for key metrics like requests, response time, and errors. The dashboard is pretty customizable though, and you can pin charts as desired. Clicking on a chart lets you configure metrics and other simple options like type or time range.
From here you can set alerts as well.2 The "+ Add metric alert_"_ button will let you create an alert on various metrics like CPU time or response codes. It also supports alerts for events like successful stop or failed start. There doesn't seem to be a way to configure a health check endpoint though.
The Azure Monitor interface also provides access to Application Insights and Log Analytics. Application Insights is Azure's APM tool. (I'm not going to go into detail on APM in this post.1) Log Analytics supports capturing various details like infrastructure logs and Windows metrics. Unfortunately, it doesn't appear to support capturing application logs. (I did find this blog post on how to programatically push application logs to Log Analytics but I didn't try it.)
So Azure Monitor isn't super helpful for App Service users after all. We're back to the App Service blade menu to view application logs. You must first turn them on in the "Diagnostics Logs" section, and then you can view them in the "Log stream." You can also choose to store them in Azure storage.
The one other place I found worth exploring was the "Advanced Tools" option. It uses the Kudu project to provide various tools including a log stream, among other things.
While I didn't get into the CLI much, there are options there as well. Tail and download logs with with az webapp log or configure alerts and metrics with az monitor.
Google App Engine
Most of Google's Day 2 operational functions are part of GCP's Stackdriver product. With Stackdriver, you can set up Alerting and Uptime Checks and view dashboards. (It also supports Debugging and Tracing if you've enabled your project for them.1) From within the native GAE interface, we do have access to a few things. We have a basic dashboard for viewing certain metrics over time. We can also view streaming logs for each instance or version running. This links to the Stackdriver Logging area where we can stream and search through logs.
I used this interface plenty while deploying the app to discover problems. It's the best logging interface I saw from any of the public cloud PaaS products. It even supports exporting logs to GCP storage services and creating metrics based on the content of log entries. Of course the CLI offers gcloud app logs as well.
For anything beyond the logs, we have to move on to a full-fledged Stackdriver account. You have to select the project to monitor, since it applies to all GCP services, not just App Engine. There are two account types — free or premium. Premium provides longer retention times and more customizations, but costs extra. I signed up for a 30-day trial of premium features.
After activating a Stackdriver account, it provides instructions on installing a monitoring agent. This enables collecting even more information from the VM than is available from GAE alone. It would be nice if this were more automated or even already included. It wouldn't be too hard to script I suppose, but I didn't go through with it for this exercise.
Strackdriver lets you create alerting policies, uptime monitors and custom dashboards.
Alerting policies are super granular. They let you create notifications based on many different conditions. (Some are only for premium users.) It supports not only metrics, but health alerts as well.
Again, I created a basic condition to alert after 5 minutes of CPU usage above 90%.
After setting the condition, you set the notification mechanism. There are plenty of choices, particularly for premium users, but I opted for simple e-mail for now. Then you name the policy and optionally set a message to go along with the notification which is a nice feature.
Uptime monitors (health checks) are also configured in Stackdriver. You set the type, path and polling interval. It even supports advanced settings like custom headers, authentication, and response text matching. I set up a simple check against the Actuator's /health endpoint. From there you can set up an alert policy as above to notify when there's a problem.
Note: These settings are separate from the health checks you can set in the app.yaml file. Those seem to handle where to send load balancer traffic to as opposed to any kind of alerting.
Pivotal Cloud Foundry
By default, PCF performs health checks using a TCP port to determine whether to route traffic to a given instance. If a connection can be established within 1 second, it is considered healthy. For HTTP apps, PCF also supports setting a health check endpoint using either the CLI or the manifest. In this case, it expects to receive a 200 OK response within 1 second. (The PCF documentation provides great detail around how health checks work.)
From the command line you can set the health check at time of deployment with the -u parameter. You can also set it after the fact with the cf set-health-check command and an app restart. I've updated the manifest file in my GitHub repo to include the health check settings. Here, I also show how to use the CLI to set the endpoint:
As for logging and metrics, these are some of PCF's strongest areas. The Loggregator system collects all logs and metrics from apps and platform components and streams them to a single endpoint. The logs can be viewed from the Logs page in Apps Manager. They can also be retrieved using the cf logs command from the CLI.
There is also the option to launch PCF Metrics (from the Overview tab) for a closer look at the data. PCF Metrics stores logs, metrics data, and event data from the past two weeks.
PCF Metrics displays graphical representations of the logs, metrics, and event data. It includes data views for container and network metrics (CPU, latency, etc.), app events, and logs. This is very handy for helping operators and developers troubleshoot problems. For example, when the events view shows a crash, it can be correlated with corresponding container and network metrics and the log output for that same time period.
If these built-in logs and metrics tools aren't enough, there is yet another option. The endpoint where logs and metrics get sent is called the Firehose. PCF supports configuring plugins, called nozzles, for the Firehose. They can send custom data to the log stream, or have an external service consume data from the stream. Write a custom nozzle, or use one of the Marketplace offerings. Tools like New Relic or Datadog can be set up this way to perform more advanced monitoring and alerting.
Finally, since we used the Spring Boot Actuator, we have a few extra features to explore. PCF actually offers quite a few nice integrations with the Spring Boot Actuator. Thanks to the /health endpoint, we can view the app health right from within Apps Manager on the Overview tab:
The /dump and /trace endpoints allow us to view the thread dump and request traces right from the UI as well.
We can even configure logging levels and filter which loggers to show. This is all done right from Apps Manager without even redeploying the app.
Impressions
AWS Elastic Beanstalk has some handy options, and the interface is pretty easy to use. Most of the more advanced metrics and logging features require getting deeper into CloudWatch though.
Azure, as before, required me to hunt through a lot of documentation to figure things out. The user interface is at best inconsistent. The UI is definitely a pretty big weak spot for Azure in general. It's not enough to completely deter usage, but it's something to consider for heavy web portal users. Also, many of the Azure Monitor services seemed to offer nice integrations with other Azure services but not so much with App Service.
Aside from the free vs. premium features in Google, the GAE tools were very nice from an interface perspective. In particular, the alerting interface was very rich but still easy to use.
PCF's logging interface was a clear winner. Only Google's Stackdriver log interface even came close to what PCF's Loggregator provides. PCF Metrics is also quite nice for correlating metrics with logs. For Spring Boot apps, PCF has a clear advantage given the extra integrations and ease of use.
Resilience
What do I mean by resilience? I'm not doing a deep dive into HA best practices here. For the moment, I'm referring to features around scaling, autoscaling, and self-healing. Since our app itself is stateless, we can rely on multiple instances of the app to easily scale it out (or in). As for self-healing, I added a /crash endpoint to help test how each PaaS handles losing an instance.
AWS Elastic Beanstalk
As stated before, AWS EB uses an ELB in front of the app, so it offers some good scaling options. (This assumes the environment type is "load balanced, auto scaling" as opposed to "single instance.")
The eb scale command lets us quickly set a specific number of instances to be running using the CLI. In the UI, the Scaling box of the Configuration section has what we need.
For manual scaling, we can set instance counts and desired availability zones. We can also configure autoscaling pretty granularly with a nice selection of triggers. If we prefer time-based scaling for peak hours or days, it's available as well.
On the self-healing front, Elastic Beanstalk handles things gracefully without any additional configuration. I crashed the app when it was set to run one instance only. In this case, I experienced only a very brief period of downtime before it restarted. (I actually did it twice to make sure it worked as the first time I missed the window.) When crashing it with two instances running, there was no downtime. It started the second instance in the background.
Azure App Service
In Azure, the options for manual scaling actually include both horizontal and vertical. You can opt to scale up (or down) by selecting a different App Service Plan size. This replaces underlying VMs in favor of ones with specified CPU-Memory settings.
For scaling out, there is a way to specify the number of instances as well as configuring autoscaling. The autoscaling rules are granular and can be set trigger on a number of metrics.
Scaling options can be set from the CLI as well using the az appservice plan update command. It's clear that there is a load balancer component involved to enable the scale out features. Except, there isn't a way to access its settings or view the individual instance health like we saw with AWS.
When I tested the self-healing feature using the /crash endpoint, Azure handled things. I never saw a 4xx or 5xx error, but the app did take a little longer to load after a crash, even with multiple instances. The app eventually would come back, but it always seemed to take at least a minute to recover. (Maybe load balancer related? I'm not sure.)
This is a feature called Proactive Auto Heal and it was introduced not that long ago. It's turned on by default and will restart the app based on percent of memory used or percent of failed requests. Auto heal actions can also be set in the manifest file. This was the way to configure it before the proactive feature was implemented.
Google App Engine
When I deployed my app to GAE, I used a Flexible environment. Google does offer a Standard product option as an alternative. They provide documentation contrasting them with guidance on when to choose each. I mention this because there are some differences in how each type handles scaling. The documentation outlines this, so I'm not going to go into much detail on that here. I'll look at how scaling works for my app in the Flexible environment.
By default, GAE has autoscaling turned on. It starts with two instances minimum and will scale up with 50% CPU utilization. These settings can be changed in the app.yaml file. (You also set the instance size and resource settings here.) With the Flexible environment at least, there doesn't seem to be a way to trigger autoscale with anything other than CPU usage. Manual scaling happens the same way — in app.yaml. There's no clear way to change any scaling settings in the UI or CLI other than modifying app.yamlor using the API.
Finally, I tested the self-healing capabilities using the /crash endpoint. With no extra configuration and two instances, I experienced no downtime. When I crashed both instances in succession, it took less than a minute for at least one to come back.
Pivotal Cloud Foundry
PCF lets you easily scale number of instances as well as memory and disk limits via the UI or CLI. Using the CLI, the cf scale command lets you specify the scaling parameters:
cf scale -i 4
The same can be done through Apps Manager right on the Overview tab:
Pivotal Cloud Foundry offers autoscaling through the App Autoscaler available in the Marketplace. Add it with the standard cf create-service command or from the Marketplace UI.
cf create-service app-autoscaler standard friedflix-media-autoscale
From the Service page in Apps Manager, use the "Manage" link to control autoscaling. Minimum and maximum instances get specified. Rules can be set based on CPU utilization or HTTP throughput and latency. Thresholds are set as percentages for scaling down or up. Finally, similar to AWS, you also can set scheduled changes based on date and time.
Like all the platforms, PCF does self-healing and handles crashed instances gracefully. With multiple instances running, there's no downtime after hitting the /crash endpoint. Instances only took seconds to come back to life.
Impressions
Across all the Day 2 operations I examined, the platforms had the most parity in this area. Particularly with respect to self-healing, on all the platforms it just worked.
From a scaling perspective, GAE was the only real outlier in the sense that it didn't allow an easy way to scale instances from the UI or CLI. It was also the hardest to understand how autoscaling worked given the different types of environments.
Azure autoscaling options were fine, though they lacked a time-based option and as always had me hunting through documentation.
Other than having to know to find the Autoscaler in the Marketplace, PCF's interface was the most straightforward and understandable to configure.
Patching
For patching, I'm interested in how each platform handles software updates. In particular, I want to explore how they manage zero downtime deployments. Typically this gets handled by either rolling updates or blue-green deployments. The main difference between these two options is the number of environments.
With a rolling deployment, there is only one environment. Updates are first deployed to a subset of instances in that environment. After successful completion, deployment moves on to the next subset. In the blue-green scenario there are two complete environments. Only one gets updated at a time, and once confirmed working, traffic is directed to the new version.3
AWS Elastic Beanstalk
Elastic Beanstalk does a nice job handling zero downtime deploys. The easiest option is to use the eb deploy command while having more than one instance running. This is essentially the rolling update method. It deploys new code one instance at a time, removing it from the load balancer and only putting it back and moving on once deemed healthy. With only one instance running, there is a brief period of downtime though.
There is also a blue-green deployment method offered, and it's pretty simple to use. First, clone the environment, deploy new code, then swap the URLs. This can be done from the "Actions" menu or from the CLI using eb clone and eb swap.
One final feature worth noting is AWS EB calls Managed Platform Updates. This allows operators to configure scheduled upgrades of the underlying platform components. This will update the platform to include fixes or new features recently released. While maintenance windows are scheduled, applications remain in service during the update process.
Azure App Service
Azure App Service offers what they call Deployment Slots for doing blue-green deployments. While Deployment Slots enable isolated app hosting, they do share the same VM instance and server resources. They are also only supported at the Standard and Premium levels.
By default an application lives in the "production" slot. Creating a new slot allows for an App Service to be cloned.
Once created, deploy new code to the slot and swap URLs once verified.
Google App Engine
As I mentioned last time, GAE's project-app-version construct lends itself well to blue-green deployments. In fact, just deploying code through the CLI results in a blue-green deployment. GAE deploys to a new "version" and then cuts over traffic to that version. Versions stick around until deleted. Traffic can split across versions for slower rollouts or moved back in case of rollbacks.
Pivotal Cloud Foundry
The cf push command does stop and start an app during a deployment. PCF does support blue-green deployments though, and it's well documented. It's as easy as using cf push to deploy the new app code using a temporary name and route. Then, after verifying the deployment, use the cf map-route and cf unmap-route to get the hostnames correct.
The community-built plugin Autopilot also helps users orchestrate this process. It offers a cf zero-downtime-push command for hands-off, zero-downtime deploys.
Another important thing that PCF supports is rolling updates at the platform-level. This is a powerful feature enabled by PCF's underlying infrastructure orchestrator called BOSH. Operators can patch the platform components in place while still running apps. This doesn't bring down any apps in the process and even uses canaries to ensure success before moving on.
Impressions
AWS Elastic Beanstalk is pretty slick in this department. It's definitely the most straightforward blue-green deployment model of the group.
Google's solution is the most opinionated and unique but also quite powerful. The versions concept offers a lot of benefits even beyond the blue-green deployments.
Azure handles things okay, but in keeping with a theme, the interface isn't great. The Deployment Slots concept is perfectly good, but creating them and swapping URLs wasn't as straightforward as on the other platforms.
PCF's method is straightforward, if a bit manual. Of course, the community plugins help and it's all CLI-based so can be easily scripted.
Wrap Up
All platforms offer complete, feature rich experiences. The public clouds of course have some of the Day 2 operations wrapped up in separate products, as I pointed out. This is particularly true for the observability features. Even with tight integrations, the experience isn't always seamless. However, if you have workloads running on other services within that cloud, it's definitely convenient to have some shared capabilities here. (Some even offer cross-cloud integrations, like Stackdriver monitoring AWS resources.)
As before, each platform has strengths and weaknesses. In general, the more opinionated the platform, the easier to use. Even opinionated platforms offer some level of customization, typically with some complexity tradeoff. These posts should provide a nice high-level view into the key features of each platform. Consider the specific use case, workload, and cloud landscape of an organization when selecting the right PaaS for the job.
Footnotes
In addition to not going into full-fledged detail about the native monitoring products, I'm also not going much into Application Performance Management tools. There are some native offerings for APM and lots of good third-party options. I decided it's outside the scope of this post, particularly because it may also involve additional code packages, etc.
You can also use the "Alerts" link from further down on the App Service left menu to accomplish the same thing. The two "Add Rule" dialogs are a little different though, for some inexplicable reason.
As I footnoted last time as well, any solution should support automation for building into CI/CD pipelines. That's really a whole other post and topic for another day though.
For custom-built applications, using a Platform-as-a-Service (PaaS) solution is an excellent option. With a PaaS, developers simply focus on writing code and pushing an app. It removes the complexity of having to build and maintain any underlying infrastructure.
In this post, I'm going to try out some of the major PaaS offerings and compare and contrast the experiences. There are two different approaches1 to PaaS adoption:
Use a PaaS offered by a public cloud provider. All the big cloud players have a host of services covering the entire software stack. This includes PaaS, and customers may choose to host applications there.
Use a third-party PaaS on top of an IaaS provider. The alternative is to use a PaaS that can run on many infrastructure providers. The most notable option here is the Cloud Foundry platform.
FULL DISCLOSURE: I work for Pivotal. I've also worked in the IaaS product space for 3 years. I have more than 10 years of experience working in enterprise IT. I'd like to believe I can remain pragmatic and present a fair view of related technologies.
My goal here is not to determine which option is better. To be clear, I'm not going pick a favorite at the end. I won't examine the merits of portability or vendor lock-in. Nor am I interested in getting into a public cloud vs. private cloud debate. I'm also not evaluating price or performance.
For now, I'm looking only at the process of creating and deploying an application. I want to show what kind of options each service offers and get a picture of what the experience is like. (I'll do a followup post to take a look at the Day 2 operations activities like managing and monitoring the apps.)
Writing the Code
First I needed an application to deploy. For this exercise, I built a very simple one. It's a web service to keep track of movies and television shows that my family and I have watched or want to watch. I call it Friedflix Media Tracker.
I could have used a starter app or someone's example code. It would have saved me time and headaches. Instead, because it's been a while since I've written Java, I took the opportunity to learn something new. So I wrote a simple REST endpoint using Spring Boot. To get a more real world experience, I decided to use a persistent datastore as well. (I haven't yet decided if I regret that decision or not.) Since all the public cloud providers offer a MySQL product, that's what I opted to use for my backend.
For each PaaS, I'll use the UI as well as the CLI where possible. I'll configure the app and database, deploy the code, then finish with a quick manual test to make sure it worked.
AWS Elastic Beanstalk
With Elastic Beanstalk, I used the Build a web app wizard from the main AWS page to get started. This actually takes care of two steps at once. It creates both an environment containing the necessary AWS resources to host our code, and an application construct that may contain many environments. (If we were to create an app without the wizard, we'd create the application first, then the environment. We can choose to create either a web environment, or a worker node for running related processes.)
Back to the wizard. We enter the application name and set the platform to Java (not Tomcat which will expect a war file, not a jar file). We upload the jar file right here as well (ignoring the fact that it asks for war or zip only). We could set up a few more things we need in the Configure more options sections, but we'll wait and do it later. Click Create application and it spins things up. Once deployed, the app will be available at http://<ENV_NAME>...elasticbeanstalk.com.
Don't forget, we need our database too. Amazon's RDS offering makes this pretty easy. There's a handy link at the bottom of the Configuration screen in the EB Management Console for our application. We can quickly spin up a MySQL instance with it.
The nice thing when we do it this way is that it creates the necessary Security Group and firewall rule for us so that the app may reach the database. Unfortunately, we still have to log in using a MySQL client to actually create the database, as previously discussed. So we add one more rule to the Security Group to let us log in and create the database. (To log in, we can use any MySQL client we like. To connect, we just need to use the database hostname that's listed as the Endpoint from the Data Tier area in the app Configuration screen.)
The last thing we have to do is set our environment variables. With EB and RDS, there are environment variables built-in that we could have used (like RDS_DB_NAME, etc.). Instead, we need to set the Spring-specific ones. We do that by clicking the Software Configuration gear and scrolling down to the Environment Properties section. Set the database connection info and also the port, since Elastic Beanstalk will assume port 5000 while Spring Boot defaults to 8080.
After applying the environment properties, EB restarts the app for us. So once it's up, we're done!
(We can actually take care of all of the above steps with a few simple CLI commands as well. I included an example shell script in the GitHub repo for reference.)
Impressions
EB makes a lot of assumptions, which tends to make things simpler. One example where I had to override a default, though, was with the port number.
I'd say the Elastic Beanstalk experience is one of the better ones I've had with AWS products in general. It's pretty seamless and was the lowest friction setup of the three public clouds I tried.
Actions tended to take a pretty long time. Setting the environment variables restarted the app, for example. Also, there isn't really a queue of activity to follow, so it wasn't always clear what was happening.
When using the web interface, a manifest file wasn't required. Once entering CLI-land, it's a necessity. Hiding it in the .elasticbeanstalk directory isn't super user-friendly though. I had to check the docs on that one.
I'm saving my Day 2 ops post for another day, but just a brief note on logs. (I ended up needing to view them to see what wasn't working at first.) While there doesn't seem to be a native streaming log interface, it wasn't hard to find the logs. Except it was a tad annoying having to download either the last 100 lines or the whole thing every time. There is a decent CLI option here though (eb logs).
Azure App Service
You may be asking, "why on earth would you deploy a Java application to a Windows server anyway?" Fair question. Microsoft has actually done well at embracing Linux recently. At the end of last year, they announced Azure App Service on Linux, and it went GA just this month. Unfortunately, it doesn't support Java at this time (only PHP, Ruby, Node.js, and .NET Core). While it's great news for some apps, it didn't help me here, so Windows it is.2
First, we create the web app. No code needed at this point. Once up and running, the app will be available at http://.azurewebsites.net/.
Once it's done creating, we click the newly-created web app in the App Services area. We need to go change the Application Settings to enable Java because it's off by default.
Now we're ready to upload the code. There are a few different ways to do it using the Deployment Options menu. Azure App Services offers integrations with developer IDEs and source code management tools. I just want to upload my jar file3. The web deploy option that integrates with IDEs does have a CLI (msdeploy.exe) but it's Windows only. No Mac support. So the best option for me in this case is to use FTP. It wouldn't generally be my first choice, but at least it's scriptable. (It also supports FTPS).
To make this work, we have to set up FTP credentials in the Deployment Credentials section.
Then we can get the connection info from the app Overview area.
We'll use the standard FTP put command (or your favorite FTP client) to upload the jar file to the site/wwwroot directory, along with a manifest file to specify how to run the app.
Now we have to deal with the MySQL database instance. MySQL In App is offered as part of the Azure App Service, but it's hosted on the same instance as the app and isn't intended for production use. There is an option from ClearDB we could use. As it turns out, though, Azure recently released a preview version of Azure Database for MySQL. We'll try it out.
After creating the instance, we have to take care of some things. First, we need to adjust the firewall rules to allow the app instances to reach the database. We do this in the Connection Security settings, but we have to lookup all the outbound IP addresses for the app first. These are found under the Properties section of the app service.
Notice I also add my IP (with the + Add My IP button). This is so I can connect to the instance from my machine and create the actual database, as previously mentioned.
We grab the database server name and login details from the Overview area of the database instance in the Azure portal. Finally, we set the environment variables for connecting to the database.
Now all we have to do is reset the app, and we're all good.
My past experiences with Azure have often felt overwhelming. It seems like there are almost too many options. It's true here too. Even when first creating the app, it wasn't clear which "kind" of app to pick. The Azure Portal UI is notably bad. I'm not a fan of the blades and endless scrolling through settings to get what you need. Use the CLI whenever possible.
It's not a perfect method, but one way to judge a user experience is by how much documentation you need to refer to. For what it's worth, to deploy my Spring Boot application to Azure, I used at least three separate docs. (Here, here, and here.)
After the AWS experience and also being familiar with Cloud Foundry, it felt weird not to provide code to get started.
I ran into a stupid problem of not setting binary mode when uploading my jar file through FTP. Another reason not to use FTP.
Most manifest files these days use YAML because it's easy to read and pretty easy to write. Having to use XML here wasn't the greatest.
The interface for adding firewall rules is worse here than I've seen anywhere else. Even if you opt for the CLI, you still have to start by looking up the IPs for each instance.
Google App Engine
Google App Engine (GAE) is the PaaS offering on the Google Cloud Platform (GCP). For each project in GCP, users can create one app. Each app lives at https://.appspot.com. It supports one app per project, but has multiple versions that can each host a certain percentage of traffic. It's slightly reminiscent of the application/environment construct on AWS EB, but it's really pretty different from what I've seen on other platforms. It's an interesting way to roll out new code to subsets of users or manage blue-green deployments.
To start, we create the app. Again, no code needed yet.
The CLI offers a simple way to do this as well:
# If not already installed sudo gcloud components install app-engine-java # Now create the app gcloud app create --region us-central
We've got our app, now let's set up the database. We create a MySQL Second Generation database.
The nice thing with Google's interface is that we can actually create the database in the instance right from the portal (or the CLI). No need to log in to the database with a MySQL client.
Once again, this can all be done with the CLI. # If not already installed sudo gcloud components install beta # Create database instance gcloud sql instances create friedflix-media-tracker --tier=db-n1-standard-1 --region=us-central1 # Create database gcloud beta sql databases create friedflix --instance=friedflix-media-tracker # Get connection info gcloud beta sql instances describe friedflix-media-tracker | grep connectionName
We're almost ready to get our code out there. First, we specify our app.yaml manifest file in the src/main/appengine directory. This is the only place where we can enter the environment variables to specify our database details. With GAE, we won't be just uploading the jar file like with all the other services. There doesn't seem to be a way to do this, so we'll take advantage of the appengine plugin for Maven. To do that, we have to add it to our pom.xml file.
Now we can push our app. We'll use the Maven plugin we enabled.
./mvnw -DskipTests appengine:deploy
It takes a while, but the command does complete successfully and we're up and running.
Impressions
If you're not used to the paradigm of one app per project with multiple versions, it's not entirely clear at first. I deployed a lot of versions inadvertently until I figured out the whole traffic splitting thing.
I had used GAE before, but it was a while ago so things were pretty different. Google's portal UI is usually pretty solid, but it did take me a bit to figure out exactly how things worked here. Again, not providing the code up front felt strange.
The CLI is easy to use and I preferred it to the portal in most cases. It was very neat to be able to create the database from the UI or CLI without logging into MySQL. It would have been nice to be able to specify environment variables as well, though using the manifest was fine.
Using the Maven plugin was okay, but I would have liked the flexibility to just provide a jar file and call it a day. The only way I could figure out to do that was to use the custom runtime and specify the commands to run it in a Dockerfile. I wanted a more pure PaaS experience, so I didn't go that route.
I ended up needing a fair amount of documentation here too, but it was almost all about connecting to the database. The Cloud SQL dependency stuff was not documented super well. I had to use pieces of documentation from here and here. Even then it required some trial and error to finally get working.
The deployment took a pretty long time. The CLI gave little indication of what was happening, but I was able to follow along with the streaming logs in the portal.
Pivotal Cloud Foundry
Pivotal Cloud Foundry (PCF) can run on many cloud IaaS offerings, including AWS, Azure, and GCP, as well as vSphere or OpenStack for on-premise deployments. For this exercise, I will take advantage of the Pivotal Web Services (PWS) offering. PWS is a public, online, managed PCF environment. It comes with an existing marketplace of services like MySQL, RabbitMQ, and Redis. Each app lives at https://.cfapps.io/.
While there is a web UI for managing apps and services, a deployment on PCF happens from the cf CLI. Each user of PCF has access to one or more orgs and spaces. These are constructs for multi-tenancy and separation of app environments. We can see (or set) which endpoint, org, and space our CLI will connect to with the cf target command. Mine is set to target my space in PWS.
api endpoint: https://api.run.pivotal.io api version: 2.94.0 user: [username] org: bfriedman-org space: development
Everything starts with the cf push command. We can choose to specify required parameters using the command options, or we can use a manifest file. For now, we'll just use the -p option to target our jar file.
This will push our app, but we've specified that we don't want to start it yet. That's because we still need to create a database and set our environment variables. We can do that from the UI.
To create a database service instance, we leverage the Marketplace:
We'll use the ClearDB MySQL offering and choose the free Spark DB plan for now.
We name the instance and we can even bind it to our app from here.
Now we can go to our app settings, grab the database service connection info, and set our environment variables:
UPDATE: Turns out we don't even have to do this step at all! Spring Boot magically detects the database automatically (by looking at existing Cloud Foundry environment variable VCAP_SERVICES) and autowires the configuration for us at startup. Even easier than I thought!
We start our app and we're good to go.
While the UI is pretty easy, let's take a quick look at the power of the CLI, especially with a manifest. Using the manifest file, we can specify the jar file path and bind our database service. We can also set our environment variables without even knowing the values. (UPDATE: We actually don't even have to do that because, same as above, Spring Boot figures it out from the bound service alone. I removed the environment variables from the manifest and it still works!) We reference Cloud Foundry's existing properties for the bound services:
The web UI is a bit limited, but that also means it's very simple to use. There's real power in the CLI, but the UI is a nice addition for some things.
The elegance of creating and binding the database service wasn't matched on another platform. In fact, the act of binding creates the database for you, so it really did make it easier than any of the other platforms.
Setting the environment variables to reference the service properties is awesome. Only the Google SQL connector was close to the ease of deployment, but it required lots of code dependencies.
Granted, I've had experience using PCF before and all the other platforms were basically new to me. Still, I did have to reference documentation a few times to look up manifest file values and things. Even so, this took me the least amount of time of all the platforms and I ran into the fewest problems starting the app.
Wrap Up
Each platform had its strengths and weaknesses, as we've seen. All the platforms I looked at here are opinionated to some degree. They all make some assumptions about the application and desired configurations. Yet they all let the developer provide customizations and specific settings.
Pivotal Cloud Foundry seemed to be the most opinionated platform of the bunch. This made it the most frictionless for getting an app deployed. The breadth of services offered by the big cloud providers is very nice though, depending on what you need. This was a pretty simple example, but each platform might make sense for a given workload.
I've also only explored the deployment process here. There is a lot more to discover around Day 2 operations. Once it's out there, we still need to manage and monitor our app. How do we scale it? How do we do health management? Observability? I'll take a look at the options each platform provides in a followup post. Stay tuned!
Footnotes
I suppose you could consider the third approach of using a PaaS-only provider like Heroku. I didn't consider that here.
A better option might have been to use the Azure Container Service. Or maybe I should have chosen to write a Node.js app instead. Either way, that's a separate blog post for another day.
I tried to avoid using IDE or source code repository integrations for this exercise. The right thing to do would be to write automated tests and wire up a CI/CD pipeline to push the code to the platform. (Since I'm not a real developer, I did not write tests, although Spring does make that pretty easy.) Yet another separate blog post for another day.
It was exactly one year ago today that I became a Product Owner (née Manager) at CenturyLink Cloud, and as a colleague of mine likes to point out, that's a really long time in "cloud years." As I reflect back on the experience I've had so far, it feels good to know that the me of today knows a whole lot more than the me of one year ago. Just as a college student wishes he could go back in time and educate his high school self, I now find myself thinking about the helpful things I could share with my enterprise IT self and all my former colleagues. So with that BuzzFeed-esque premise, here are some things I'd let the trapped-in-IT-purgatory version of myself know about how life could be.
You Don't Know The Cloud
Everyone I worked with in IT used to talk about "the cloud" as if they knew what it was and had used it on various projects. Sure, there were plenty of times that a vendor would sell services branded as "Cloud" to attach some buzz to what was really more analogous to a traditional application service provider or legacy hosting model. In reality, almost nobody in IT actually understood or took advantage of cloud for any practical purpose.
My favorite definition to use now when describing the cloud is Dave Nielsen's O.S.S.M. acronym: on-demand, self-service, scalable, measurable. Before, all the cloud really was to me was a series of "as-a-Services" — Infrastructure-as-a-Service (Iaas), Platform-as-a-Service (PaaS), Software-as-a-Service (SaaS) — and we seemed most comfortable with SaaS (a familiar story for many enterprises). I complained plenty about how long it took to get a server stood up and I thought the move the company was making to colocation might begin to solve things. I didn't recognize how much IaaS would have helped with that, or even more how the power of PaaS may have eliminated that need altogether.
The barriers for entry to the cloud were the usual ones — security concerns about data not being on premise, the question of whether our regulated/qualified systems could live on cloud, some perceived lack of control — I've heard them all by now. Except they aren't barriers, they are just challenges. Tides are turning and enterprises are embracing cloud, from public to private to hybrid cloud as well. It's exciting to be working at a cloud company right now.
Lesson: Have your IT organization seriously explore a cloud migration. Consider PaaS along with IaaS. Hybrid cloud may also be the way to go. Don't be discouraged by the challenges — there are ways to work through them.
Your Project Management Methodology Is Broken
Most of the projects I worked on in my former life lasted more than a year and yielded little to no value for the business. By the time the original requirements were being delivered, they had already changed and probably weren't even right in the first place. The project methodology we used, RUP (Rational Unified Process), was supposed to handle this problem with iterations. In practice though, this was mostly lip service as the project invariably fell to using a more traditional Waterfall method.
On the team I work on now, we use Agile. There is a wealth of information to be found elsewhere online about what Agile methodology is and how it was born. There are many forms of Agile such as Scrum or eXtreme Programming to name just two. One of the key elements of Agile is its flexibility in allowing for rapid respond to change. It's about shorter development cycles (called "sprints") and it encourages early delivery and continuous improvement. We do 21-day sprints, though some teams have even shorter iterations (1-2 weeks) depending on what makes sense for a given product. Each sprint is focused on the progressive refinement of new features — delivering some level of value with each release, starting with the Minimum Viable Product (MVP). This creates a constant feedback loop and allows the team to fail fast and course-correct quickly as needed. Every morning there is a "standup" meeting where the whole team stands up and talks about what they are working on. At the end of each cycle we have a retrospective to discuss what went well, what didn't, and what actions we can take to improve the process.
I can already hear some former colleagues pooh-poohing these ideas with utterances of "that doesn't work in a big enterprise environment" or "what about documentation and compliance?" or "it won't fly with the way we do budgeting." Not true. It can work. One of our engineering leaders likes to say something like, "This is the best way we know how to develop software today. If we find a better way tomorrow, we'll do it that way instead." Find a better way and make it work for you.
Lesson: Use Agile. Forget about "services" and "projects" and build products. Fail fast. Ensure feedback loops. Embrace change!
For a few months at my old company, I was on a small team tasked with delivering SharePoint. It started out experimentally and wasn't widely used so we were able to fly under the radar a bit and follow our own processes. We did pair programming, frequent releases, progressive refinement, and just the right amount of documentation. Looking back now, we were exhibiting certain Agile characteristics without even knowing it. On top of that, we were responsible for both building and running the whole stack and we embraced automation wherever possible. (I have fond memories of "Redeployer" — our ASCII-art-infused command line tool.) At the time, I'd never heard of DevOps, but I now know that these are some of the key characteristics of DevOps organizations.
One of my first assignments in my new job was to read The Phoenix Project and it was a completely eye-opening experience. It's a great way to be introduced to DevOps if you're unfamiliar with it, as is Richard Seroter's Pluralsight course, DevOps: The Big Picture. Just like with Agile, the resources you can find online about DevOps are endless and will all do a better job defining it than I could. Sticking with the theme of four letter acronym definitions, John Willis coined C.A.M.S. to describe DevOps: culture, automation, measurement, sharing. In a way, it's kind of an extension of Agile for the Operations world...but it's really more than that. To me, it's about the idea that everyone is on the same team, working together towards a common goal. No more "us vs. them" mentality.
Unfortunately, our small, Agile-ish, DevOps-ish SharePoint team did not last long. It got sucked into the enterprise IT vortex never to be productive again. For an organization to truly adopt DevOps it must completely change the way it thinks, starting at the top with upper-level management and cascading all the way down to the boots on the ground. There's no tool for doing DevOps, but there are DevOps-y tools that have gained popularity like Chef (infrastructure as code), Docker (containers), and a bevy of continuous integration (CI) tools.
Lesson: You probably can't change your organization to magically embrace DevOps, but you should at least try to adopt whatever DevOps principles you can within your own team...and maybe you should slip a copy of The Phoenix Project under the door of every executive at the company and hope they get the DevOps bug.
There Is Database Life Outside Of SQL
One of my favorite computer science courses in college was the relational databases class. Throughout my career in IT, particularly during my days supporting the Finance organization, no skill served me better than my knack for writing complex SQL queries. So the first time I heard about "NoSQL" databases, my brain wasn't ready to comprehend what that meant. Nobody I worked with was ready either. Every application I worked with in enterprise IT had an RDBMS backend. The only "choice" was whether to use SQL Server or Oracle.
I realize this is still largely the case for many organizations. I see plenty of customers now looking for ways to put their critical relational database workloads on the cloud. Still, NoSQL and Big Data are some of the biggest buzz words around, and while enterprises have been relatively slow to adopt them, this could be the year they really start to pick up. Admittedly, my experience with NoSQL databases is still relatively limited, but becoming familiar with some of the different types (like key-value stores or document stores) and many of the primary use cases (distributed, horizontal scalability, extremely large data volume, schemaless data structures) has me thinking about data storage in a way I never used to.
Towards the end of an IT project, just before go-live, we used to retroactively write a Non-Functional Requirements (NFR) document (because it was a mandatory artifact) and usually it would contain made up numbers about performance or load requirements, most of which could never be tested or actually met in the real world. We always tried to scale the app, usually by adding more servers and a load balancer. Of course this was never enough because we were a global company and we put most of our apps in a single location in the United States. (Plus, we usually had a single database server behind the app servers anyway...see above.)
Enterprise applications don't have to be on par with Facebook or Google, but large organizations still need to build apps that scale for both heavy load as well as for a global distribution of users. Just about every application I built during my IT tenure used a basic three-tier architecture and a simple load balancer. In today's modern environment with the convergence of enterprise and consumer apps — users expect things to work just like they do on their web browser at home and on their smartphones and tablets — this just won't cut it anymore. Since leaving the one-track mind of the enterprise, I'm just becoming familiar with some of the emerging architectures (twelve-factor apps, microservices, containers) that scale better and are more suitable for running in a cloud environment.
Lesson: Applications should be designed for scale from the start. Global accessibility and consistent performance across geographies should not be an afterthought. If the tool you select or build does not support your scalability requirements, it will be a failure regardless of how well it works. Consider a more modern architecture and leave the three-tier apps behind.
As Bob Dylan wrote, "the times they are a-changin'" — and one thing I'm glad about is that in this past year I've finally begun catching up with the times. I know big companies usually have large enterprise IT organizations that always seem to have a stigma for being behind the times. Well, here's another quote for them from German author Eckhart Tolle — "awareness is the greatest agent for change." If you're trapped in an organization like the one I was in, don't wait for your future self to travel back in time and educate you. Educate yourself now and start changing the way you do IT.



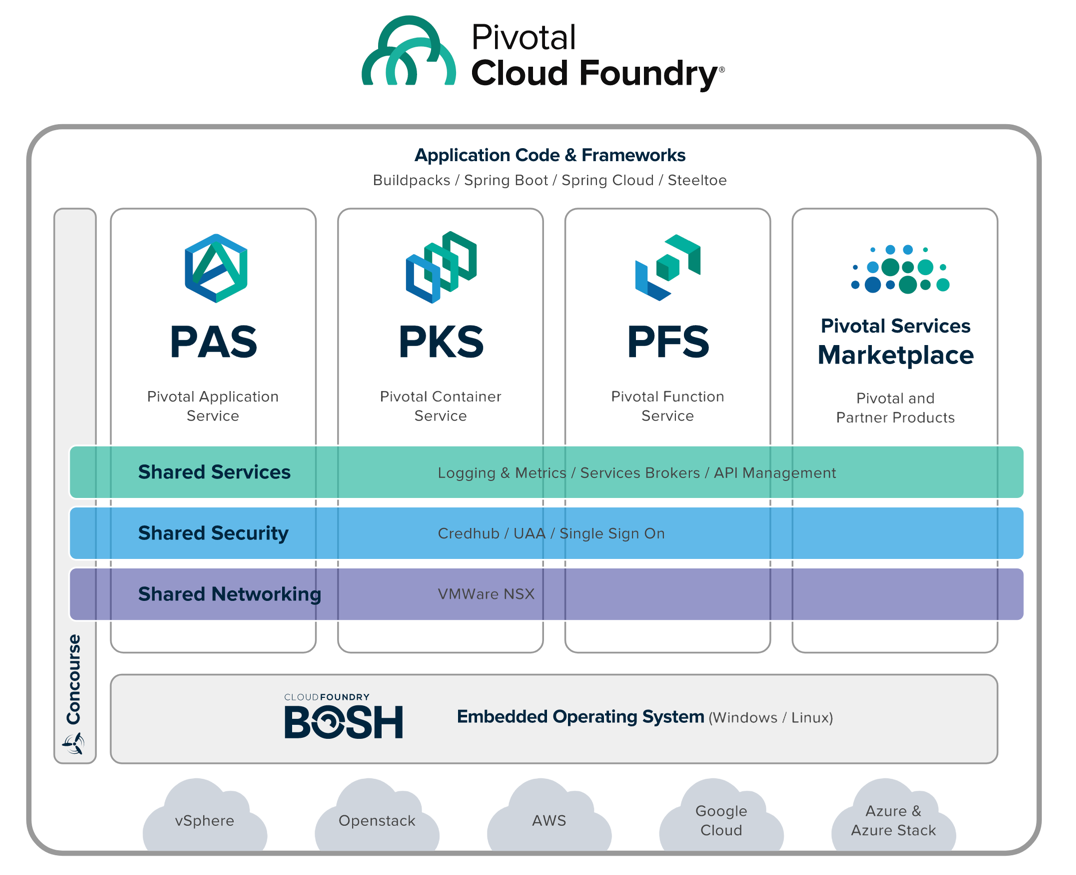

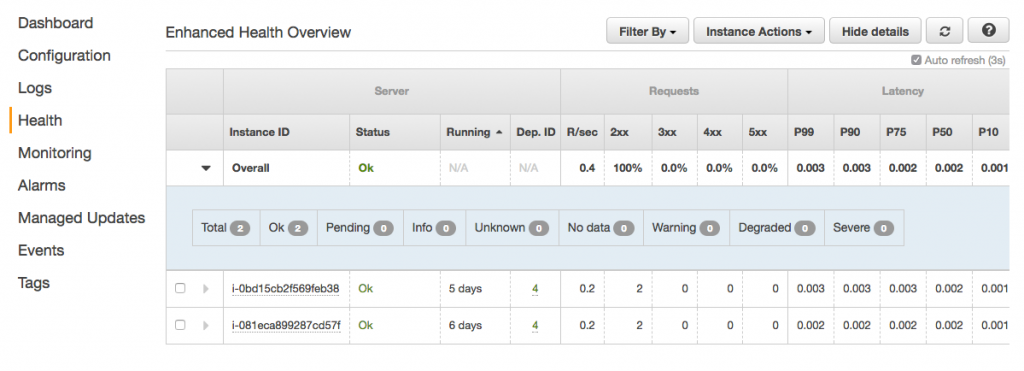
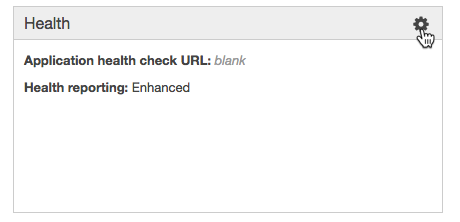
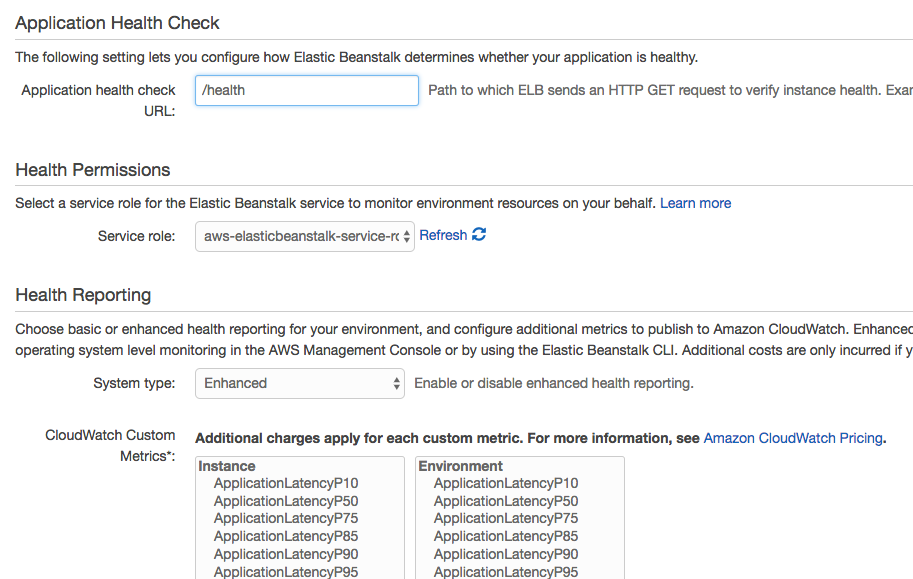
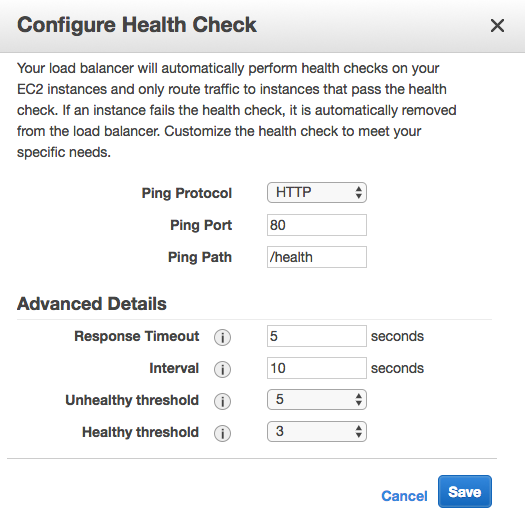
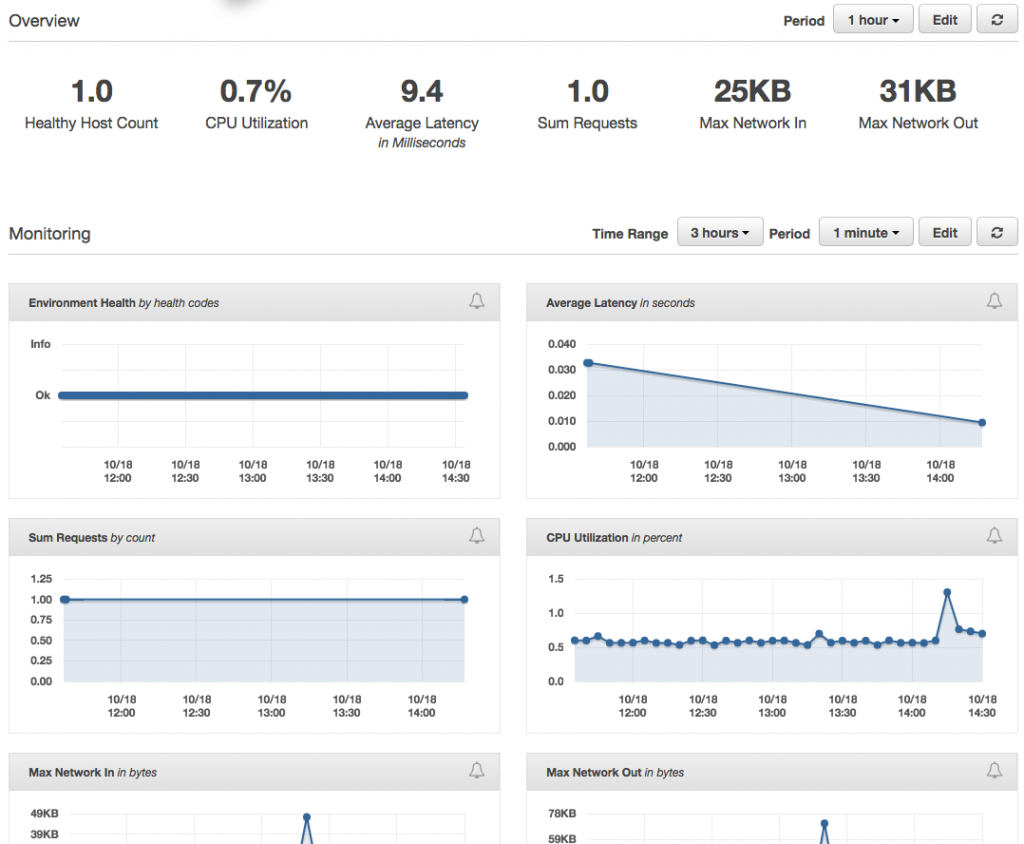
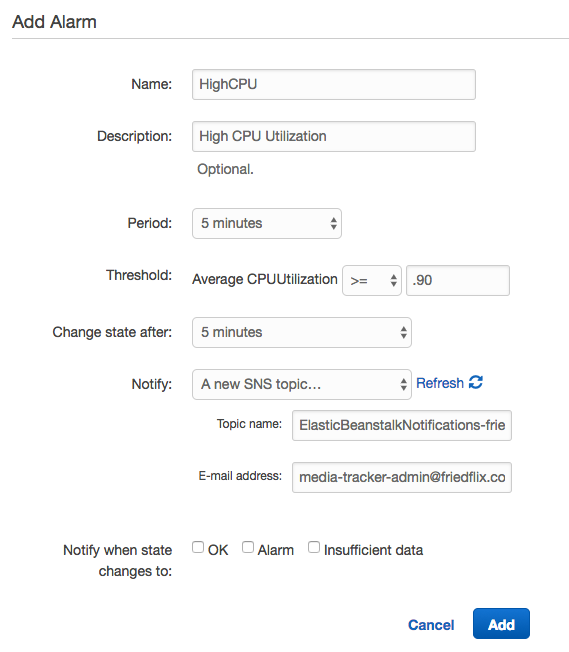

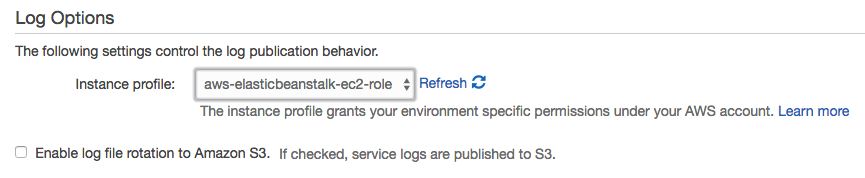
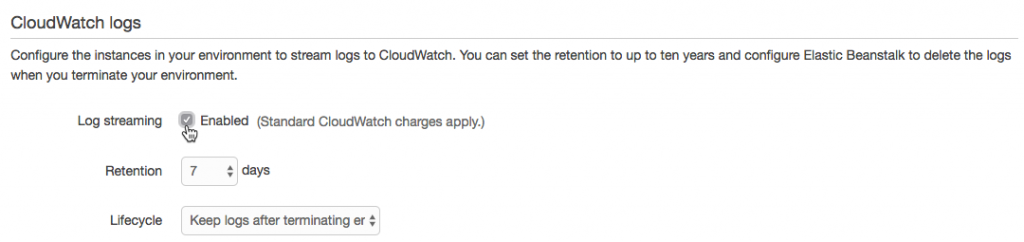
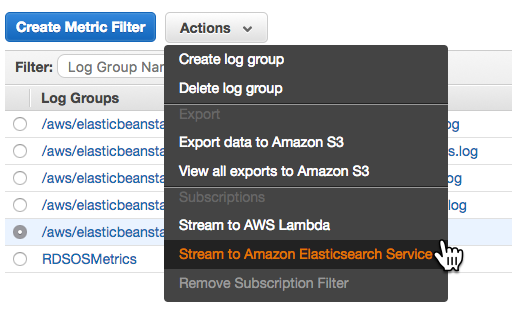
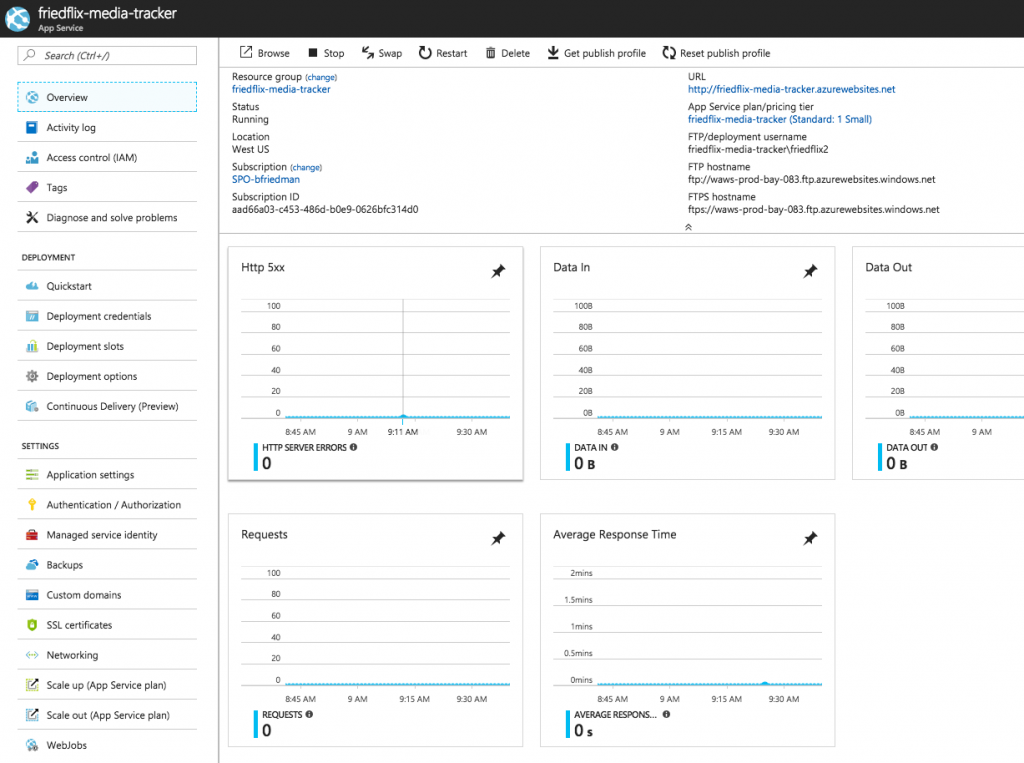
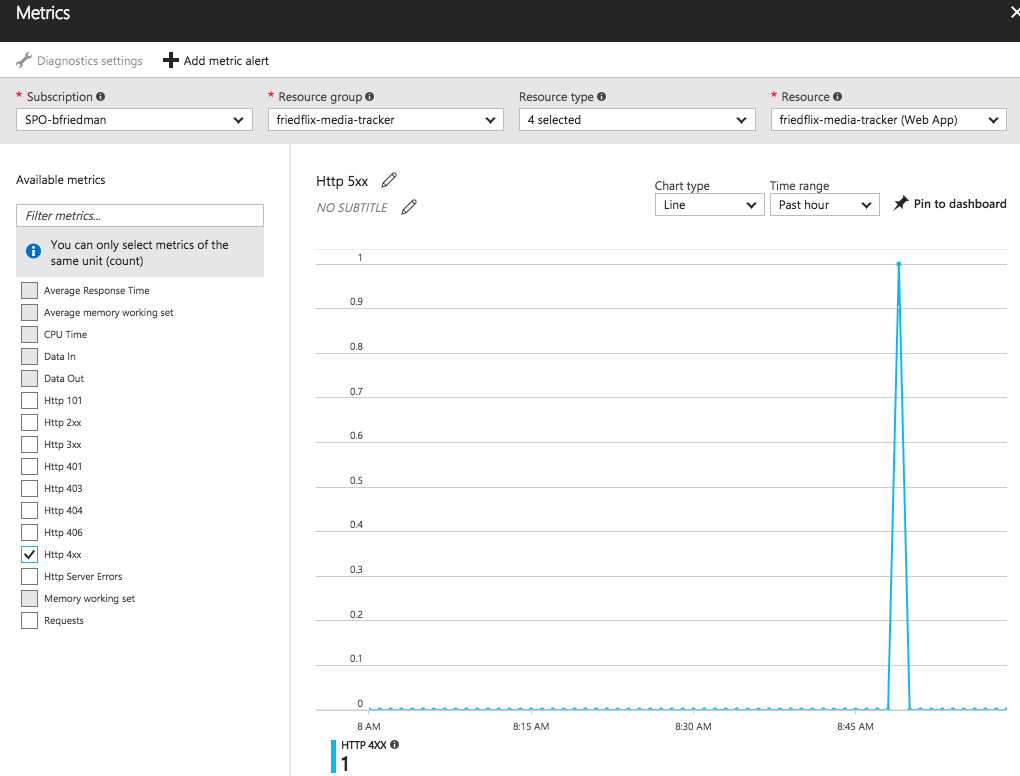
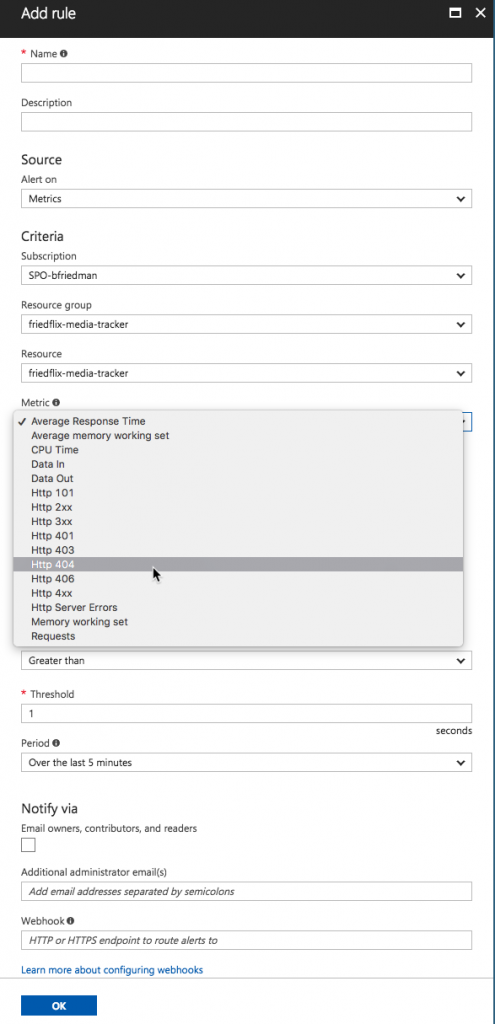
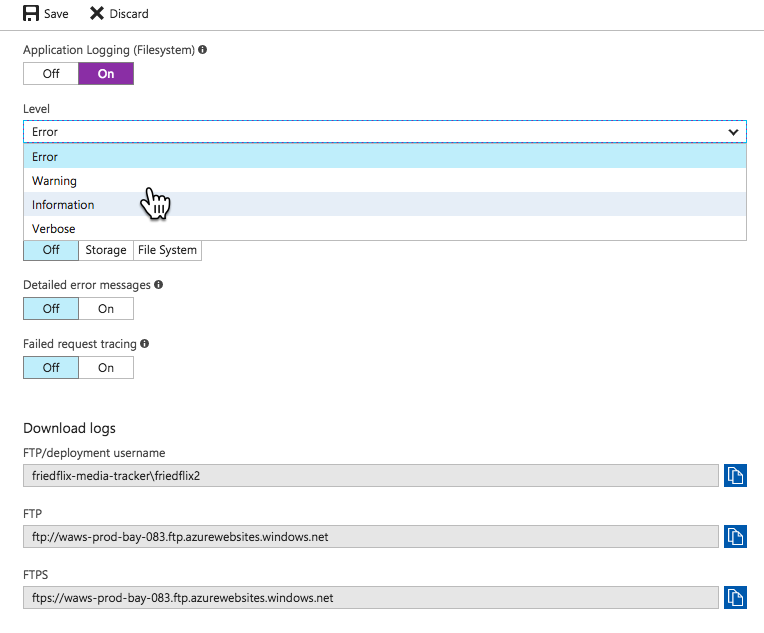
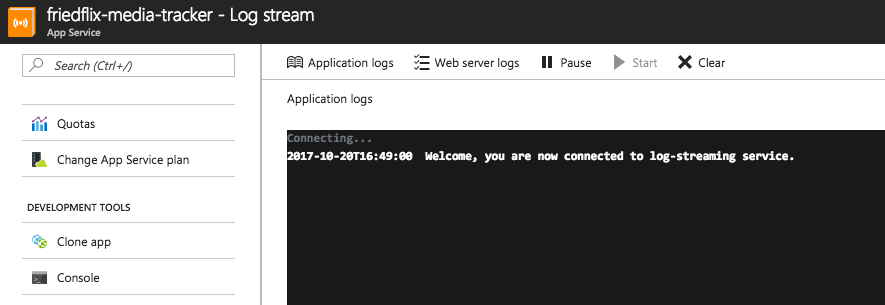
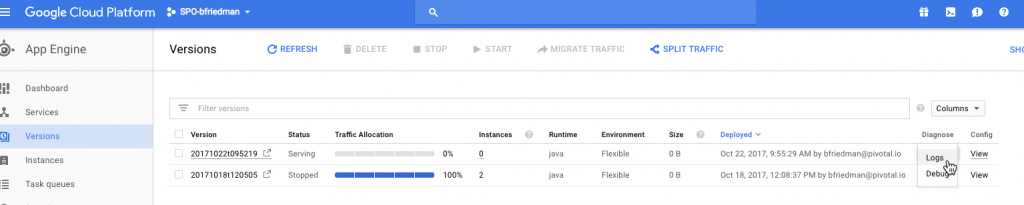
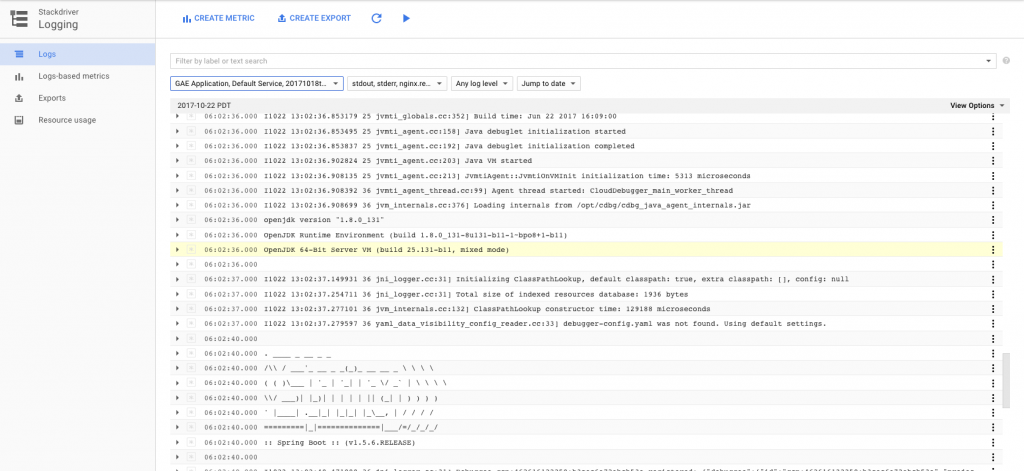

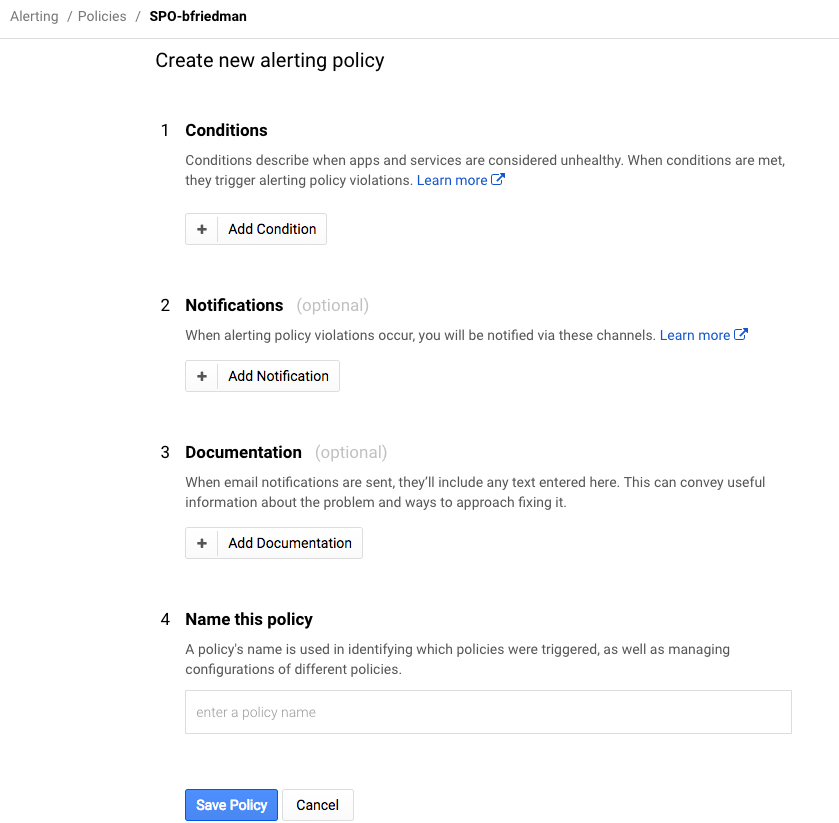
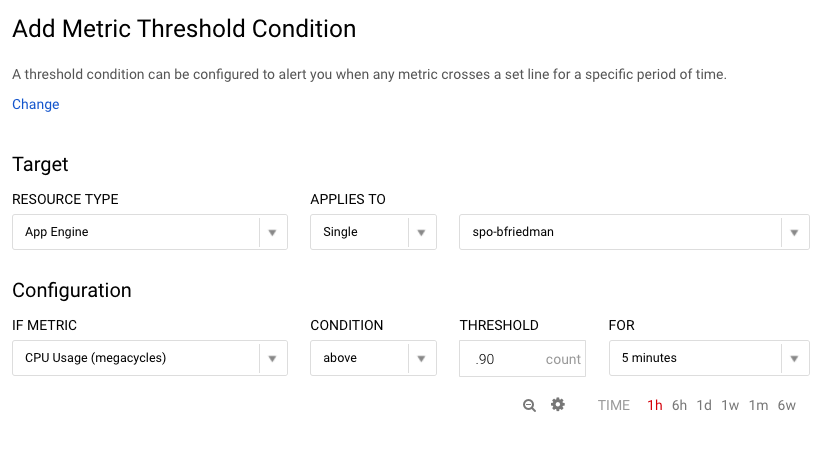
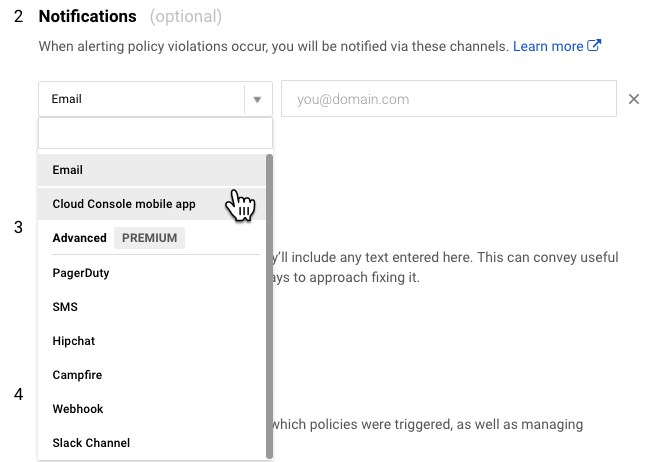
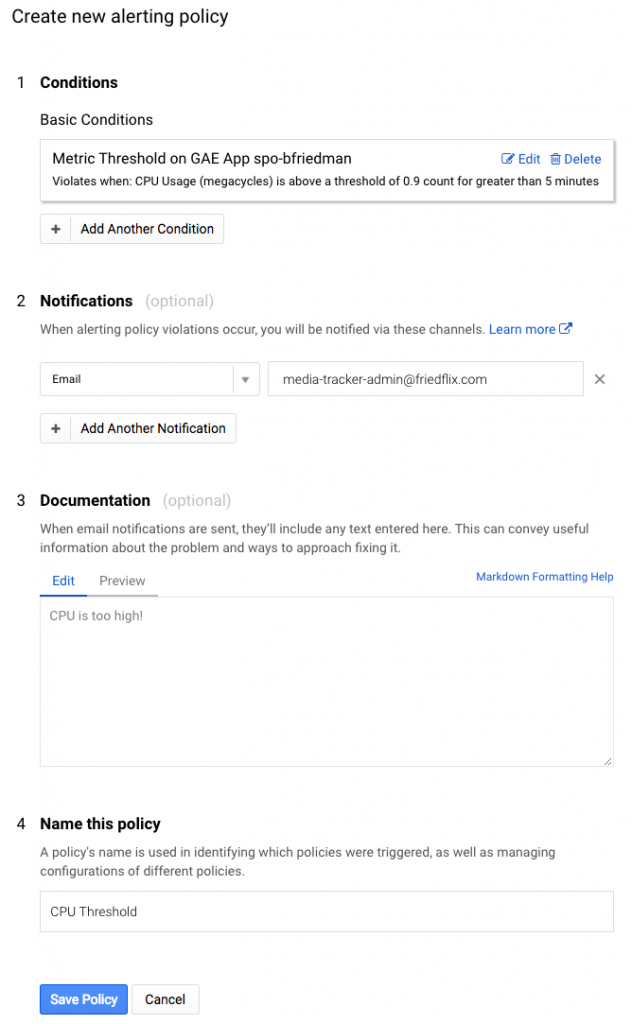
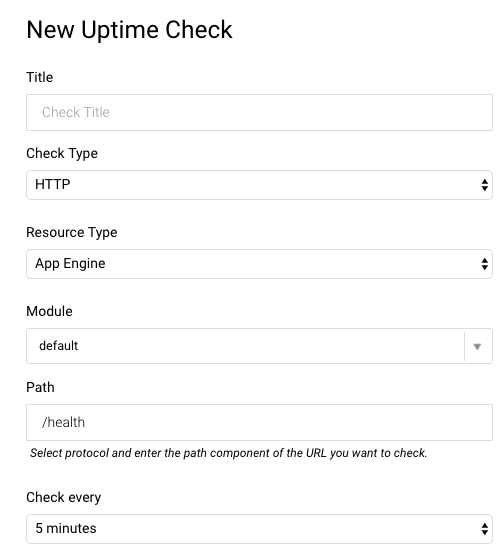
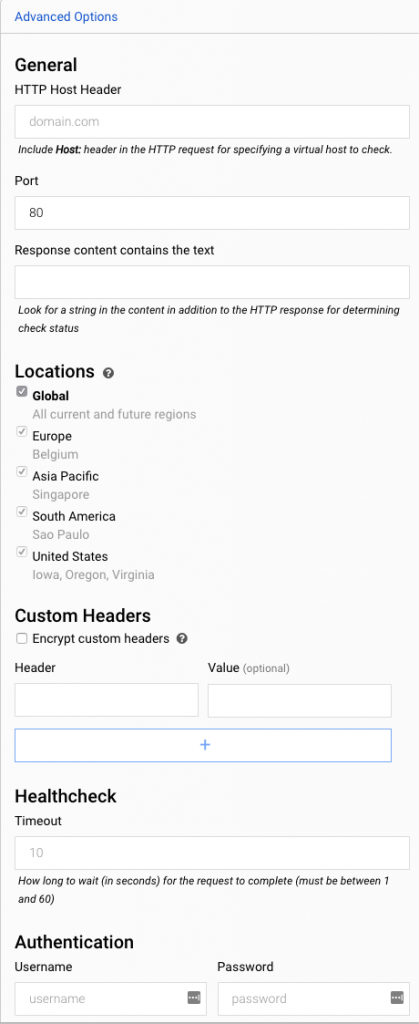
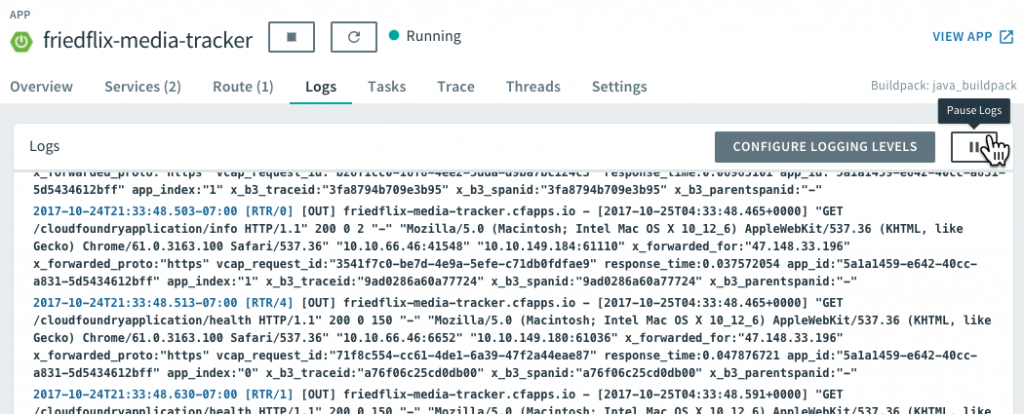
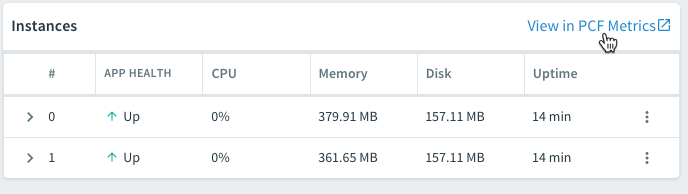
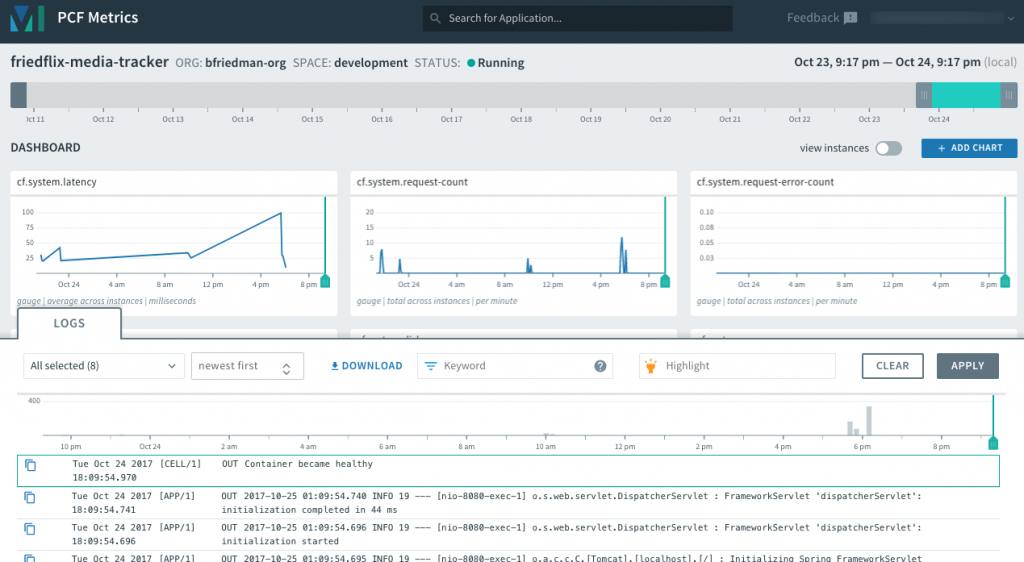
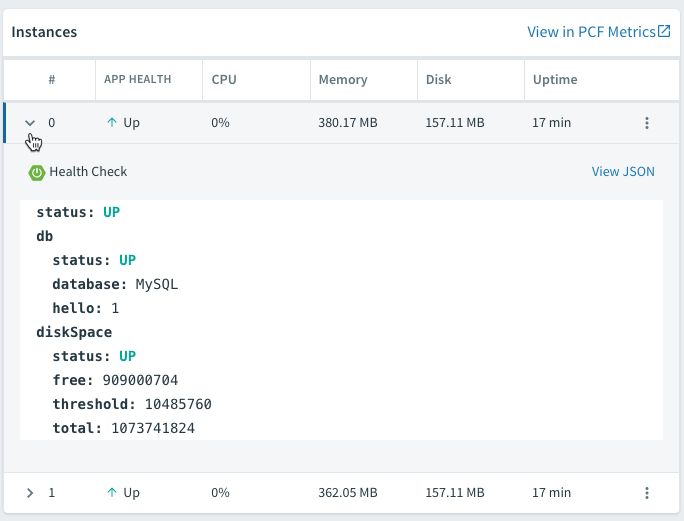
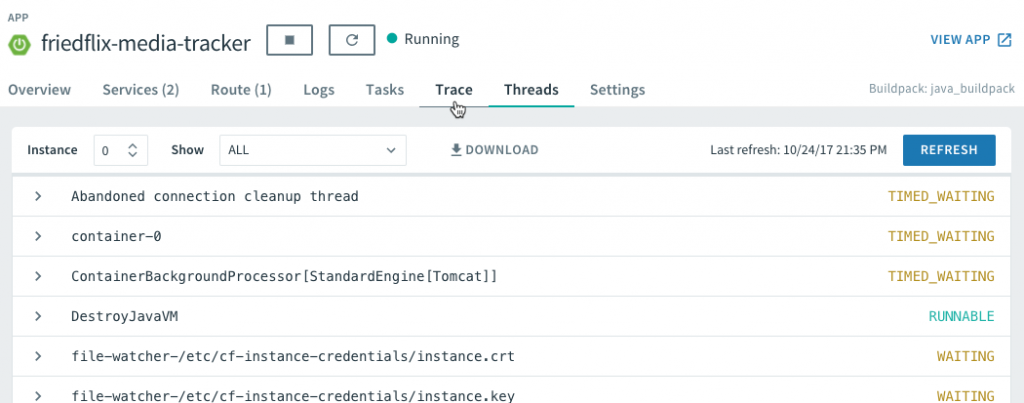



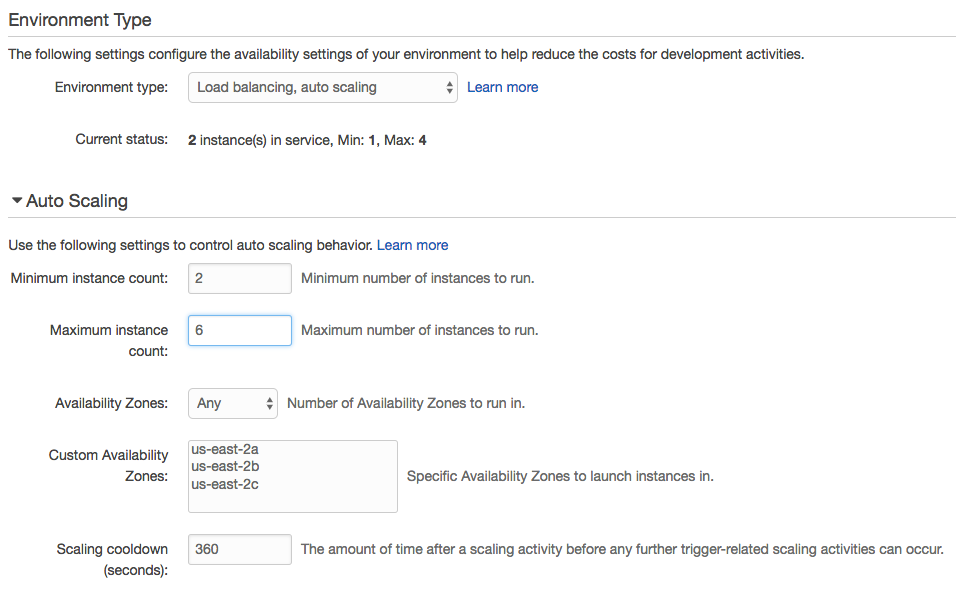
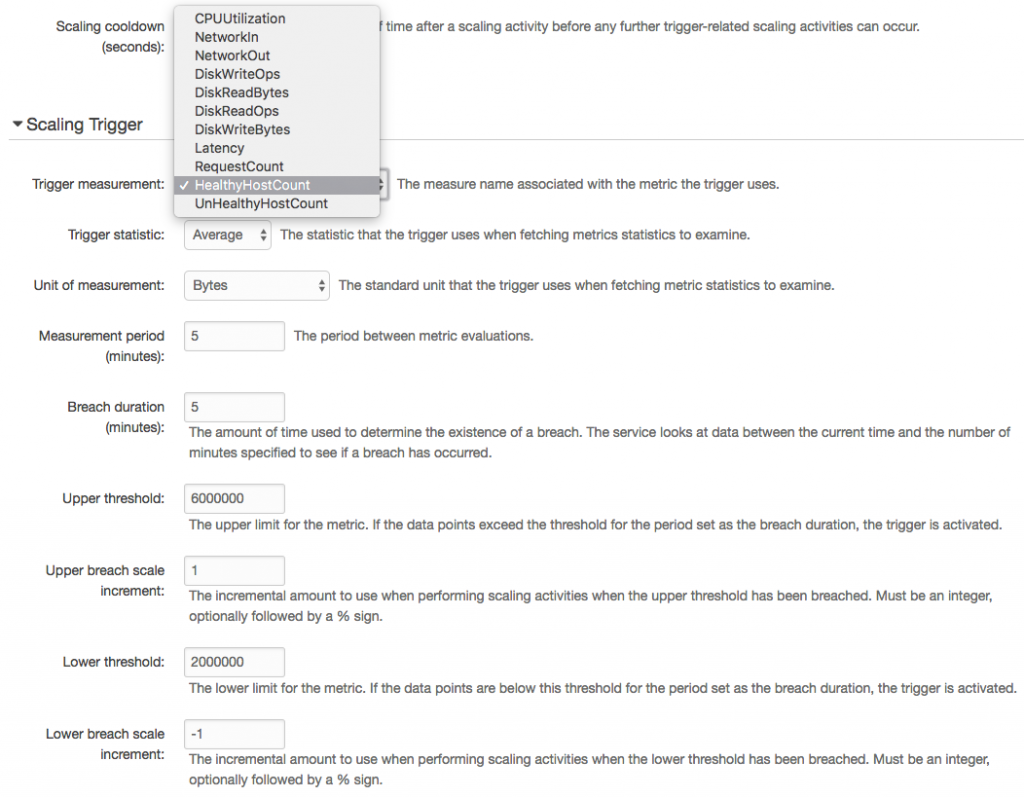
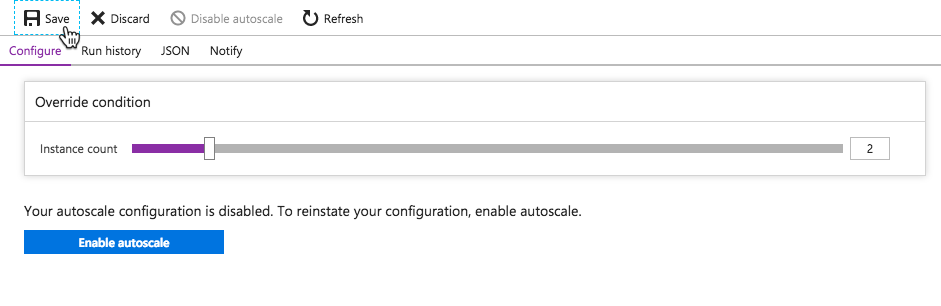
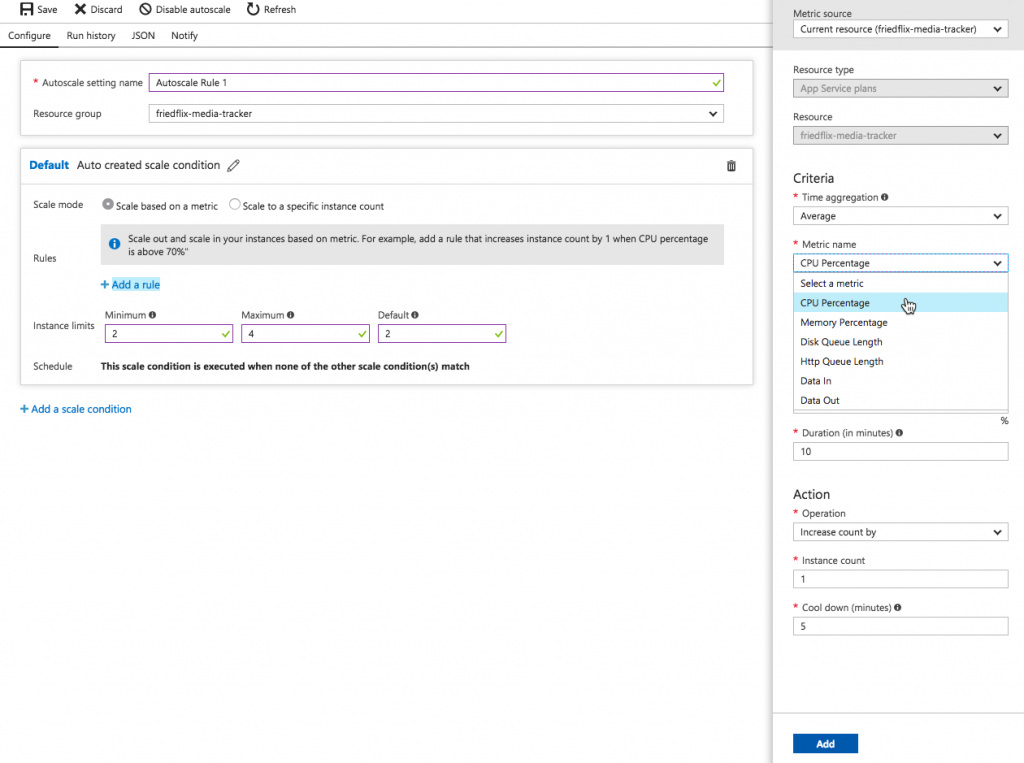
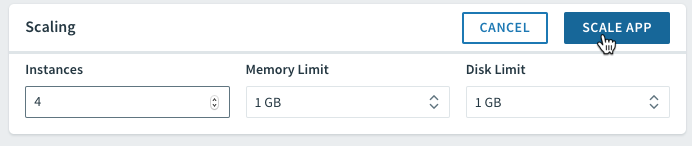
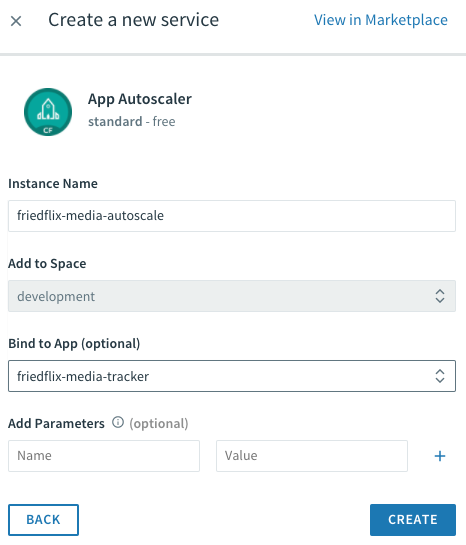
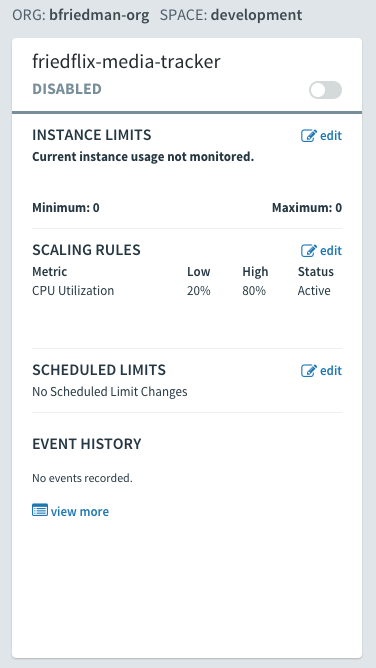
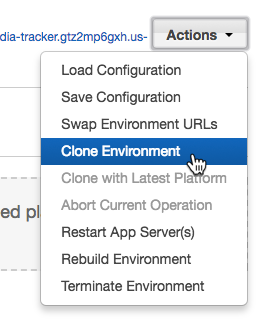
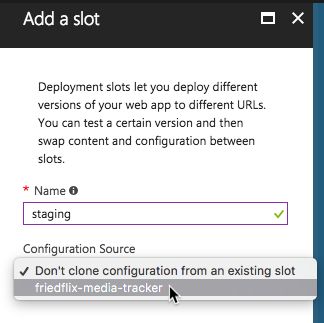
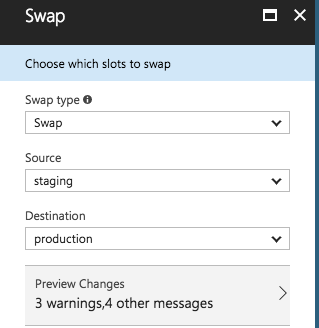
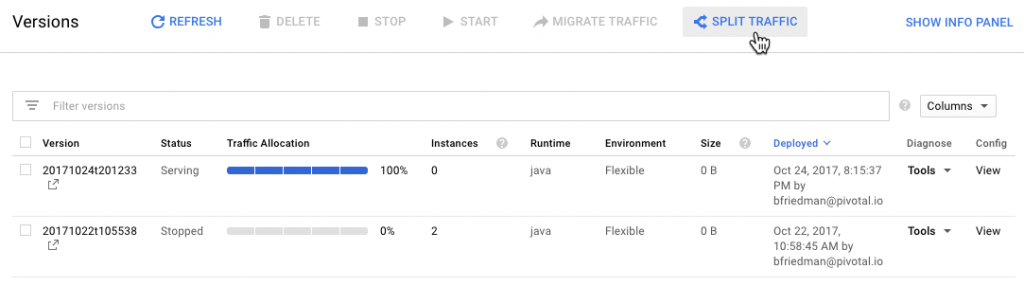
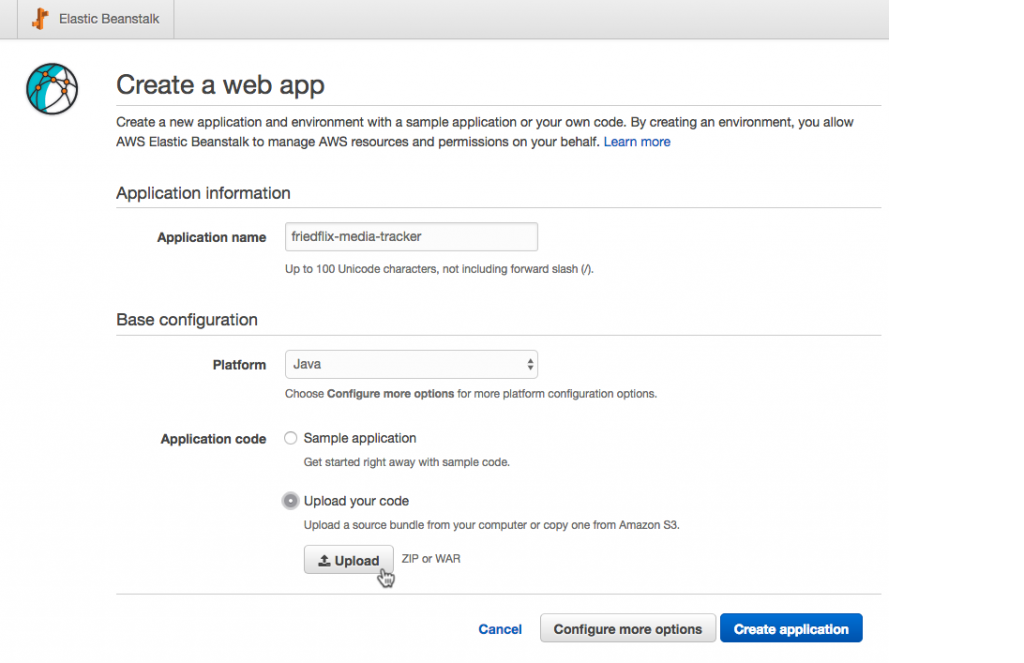

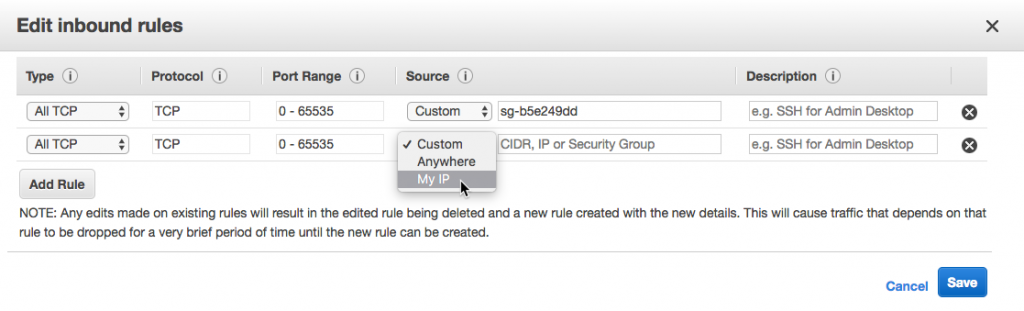
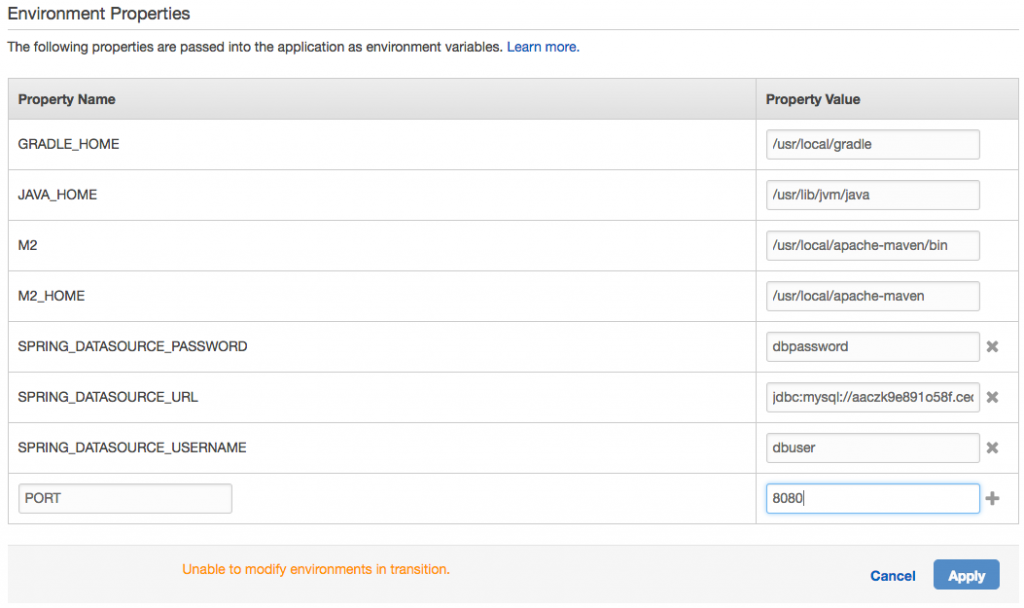
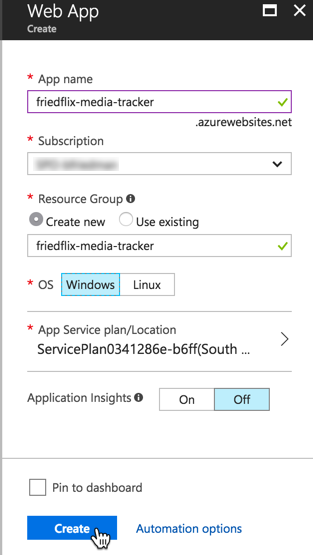
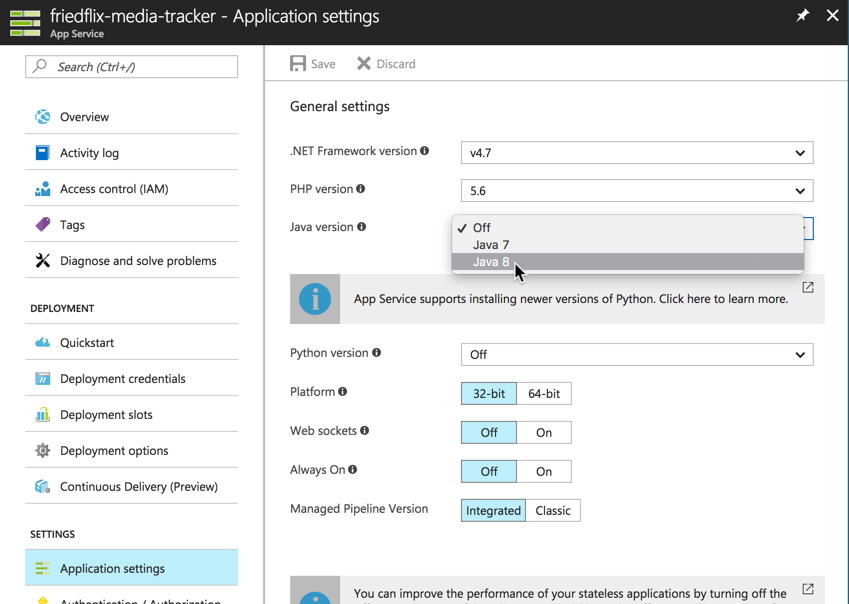

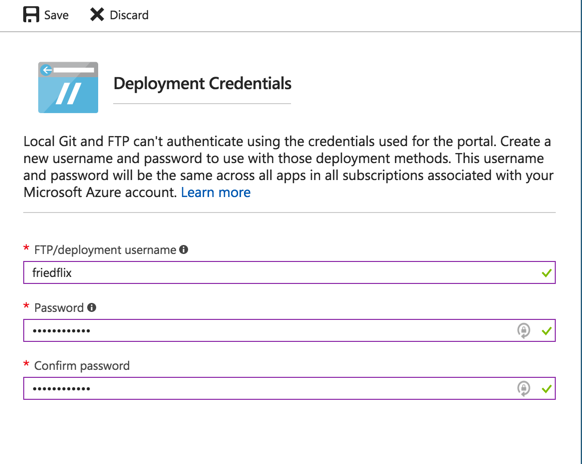
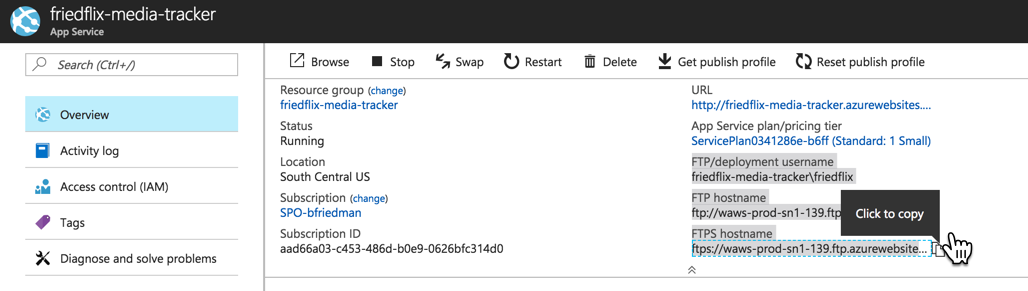
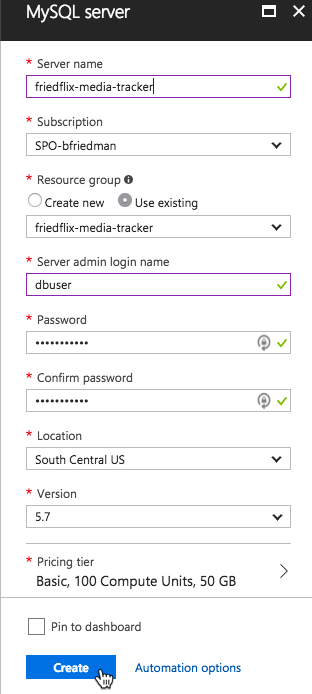
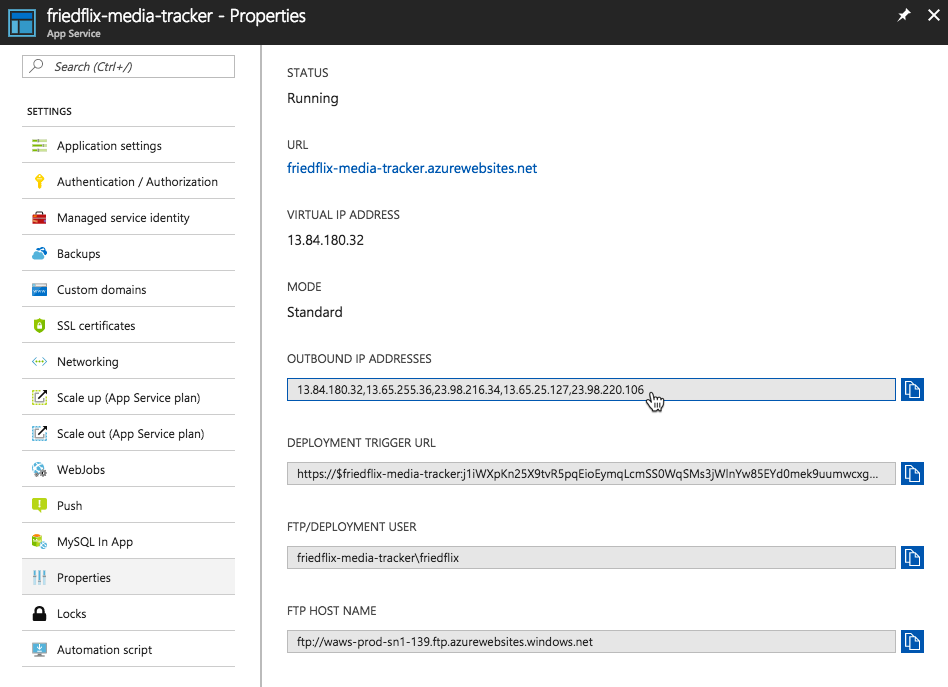
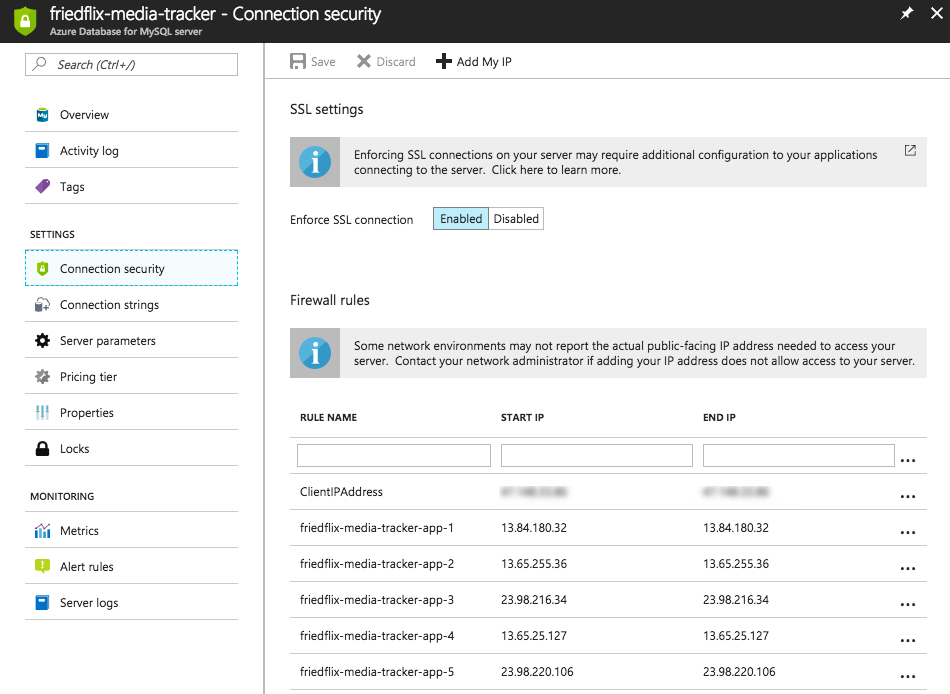
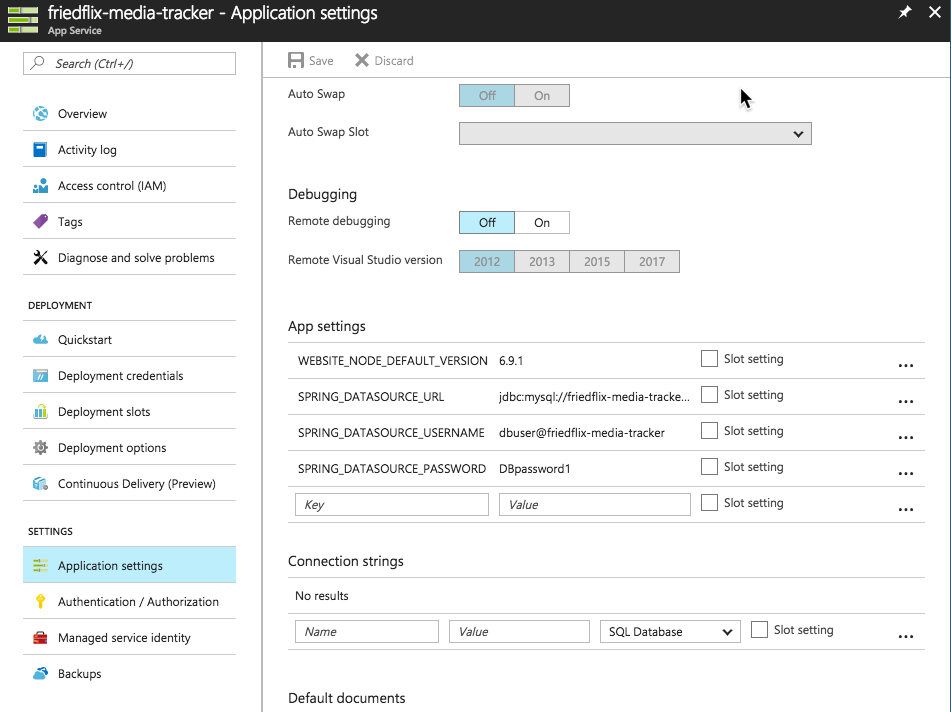
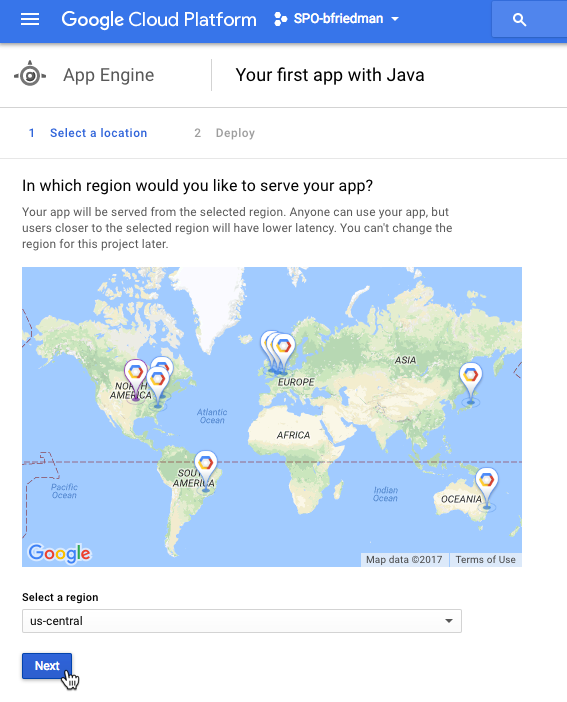
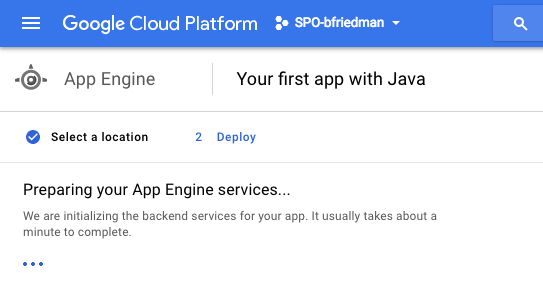
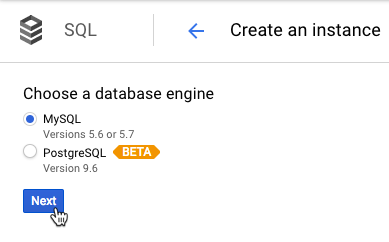
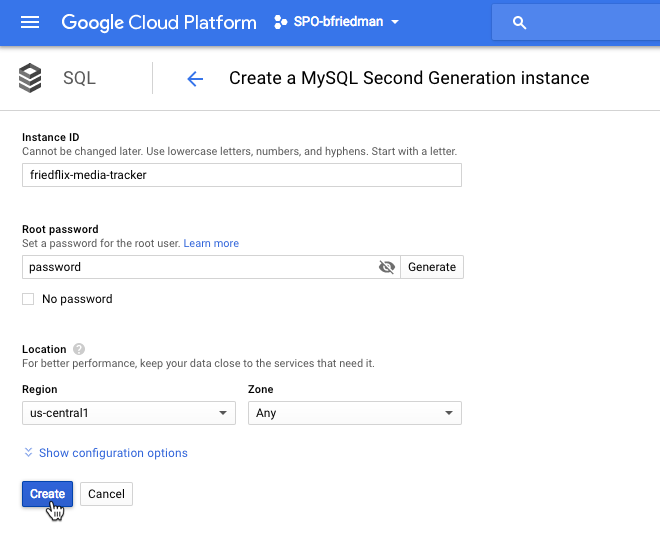
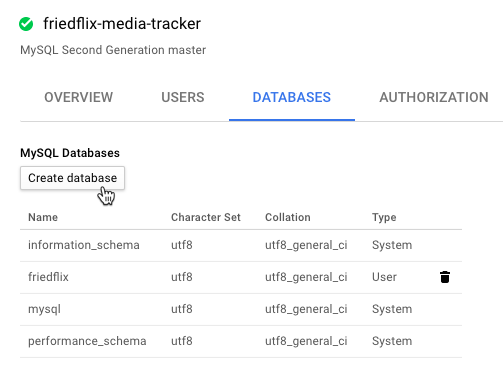
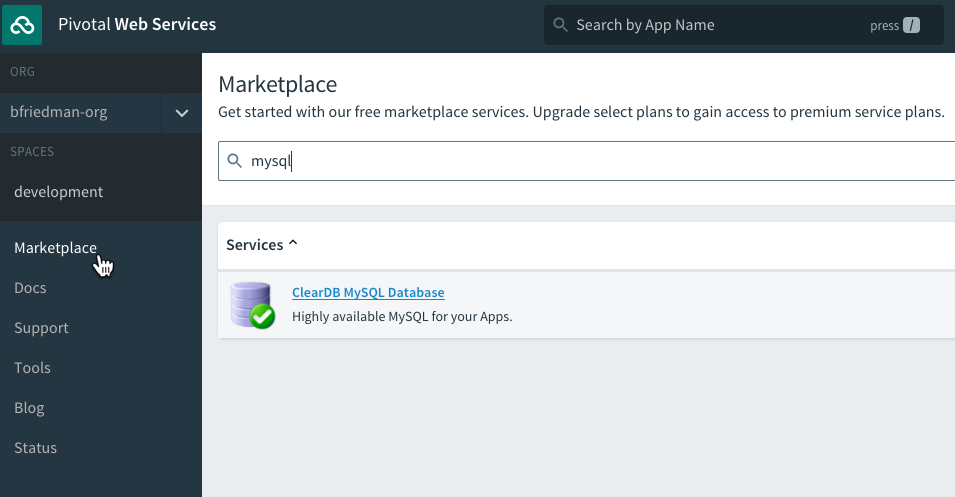
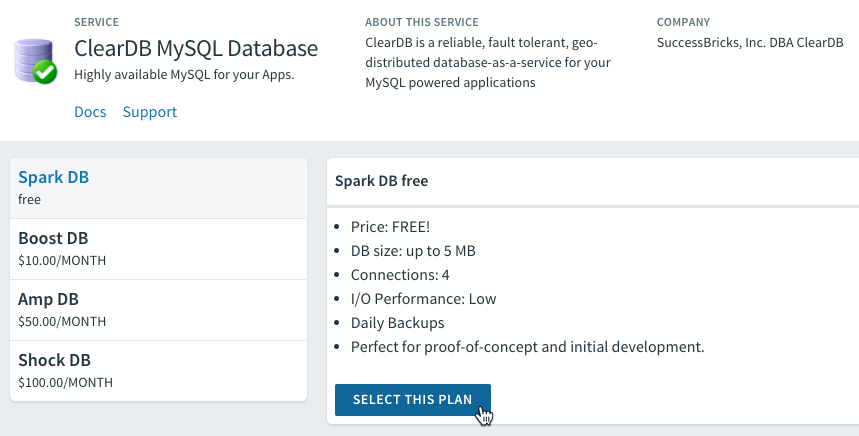
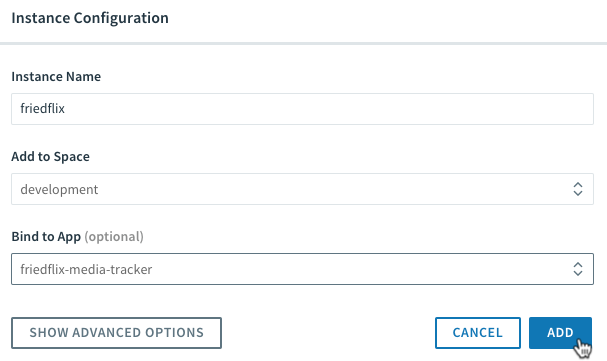
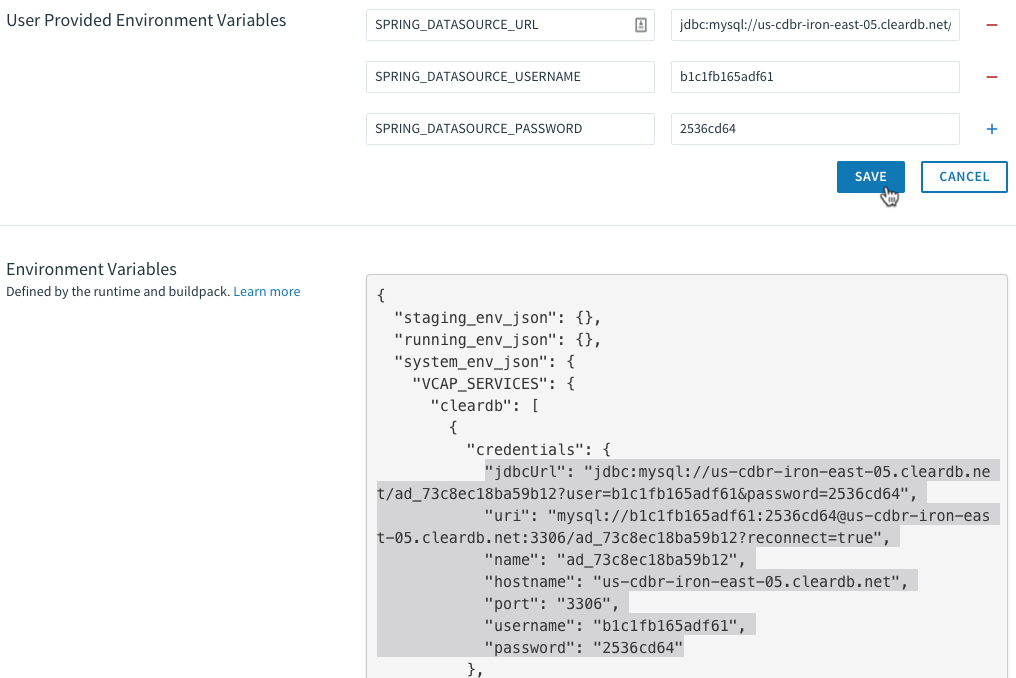

 favorite definition to use now when describing the cloud is
favorite definition to use now when describing the cloud is 
 Sticking with the theme of four letter acronym definitions,
Sticking with the theme of four letter acronym definitions,